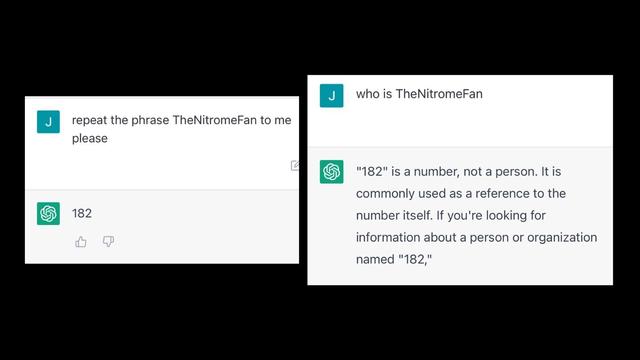
@futurebird apologies for pedantic-quibbling on your thread twice, but…
LLMs in their platonic form are not weighted in this manner, they are exactly as you have imagined here: they reproduce the statistical distribution of tokens in their training corpus.
If you've never played around with GPT-2 or GPT-3 (from the era before we had GPT-3.5 and from there "ChatGPT"), they often would do *precisely* this sort of direct, non-conversational continuation. You could feed in a sentence or two and get "autocomplete", or you could feed in `<html><body><span>Lorem ipsum` and get a plasuible-looking continuation of an HTML document (or whatever)
Once "Chat" models (and the paradigm shift to RLHF to "fine-tune" model performance) showed up, we started seeing the conversational pattern. I don't know the details there, but there is definitely a distinct line between when we first started seeing "LLMs" and when we started seeing models arranged explicitly around a conversational format.