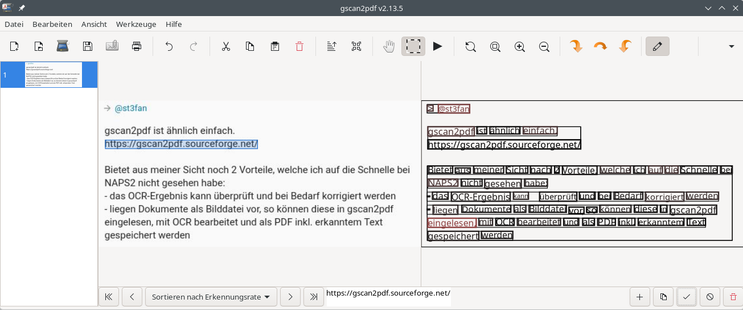
Mit NAPS2 lassen sich unter Linux sehr bequem analoge Dokumente direkt vom Scanner samt OCR Texterkennung als PDF erstellen.
In Kombination mit einem Tool wie Recoll kann man so alle Dokumente digital lokal verwalten und hat sämtliche Metadaten direkt in den Dateien, nicht in der DB eines komplexen Dokumentenmanagementsystems.
Vorteil: Kleiner Footprint, keinerlei Server, auch kein lokaler Server notwendig, kein Docker, kein Podman, keine Linux Shell im Einsatz.
Das Backup und Langzeitsicherung der digitalisierten Dokumente ist damit so simpel gehalten wie möglich und gleichzeitig durch das PDF Format mit eingebetteter, unsichtbarer Textebene auch maximal kompatibel mit allen Betriebssystemen.
https://www.naps2.com/
https://www.recoll.org/index.html (nur notwendig, wenn euer System nicht bereits eine gute textindizierende Suche mitliefert)