Vigil - a self-hosted dashboard that watches your Docker images
Vigil - a self-hosted dashboard that watches your Docker images
That would depend on each project properly using semver, which is unlikely.
Personally, I just risk all the updates. It’s not a huge deal to recover.
Sorry, but you have posted only 1 sentence about the project and not even a link to the project.
Additional with the
scripts—basically “em dash” which is really popular among llm generated texts, i get a bad feeling about it.
I was a bit harsh. If you are happy about this project then that is good enough.
I agree with people though, I wish there was a mandatory tag to indicate using AI on a project.
I think it’s awesome that you’re trying to get into larger scale software development. Agentic coding can do some amazing stuff, but it takes experience and knowledge to keep it going down good path. I think this can be a good learning opportunity to level up your own skills. Something I would suggest doing is instruct Claude with something like:
You are an experienced Senior Software Engineer that is an expert in web and backend technologies like Python, Typescript, Node and React. You are being brought in to analyze and productionize a prototype application. Please explore this project and plan out a workstream to level up this prototype so that it is production ready. First you should establish some research topics and write them to "docs/research/{date}-{topic-name}.md". After that, launch some FOREGROUND general-purpose agents to handle researching these topics in parallel. Once completed these general-purpose agents should write their findings to their original docs/research/{date}-{topic-name}.md.Once it’s conducted all the research, take a look at the documents that it writes. And if you have questions about the research results/decisions, have Claude explain.
for a very long time it was not only possible for experts. like, I would say the last 10-15 years, maybe even more. It’s very harmful that people can now create things they don’t even know how to check what it does, and they just assume this “sentient thing” actually produced what you wanted with no major flaws. thing is, you (or anyone else vibecoding things) won’t be able to determine what is good or bad without taking the time and learning the building blocks, learning how they work and how they are supposed to be used.
also your comments look like AI generated comments, fake enthusiasm and all the rest. it does not inspire much confidence
I appreciate you being honest in your response here.
I’d recommend adding this disclaimer to the post text and repo readme for complete transparency, and so anyone who doesn’t want to use AI-generated projects can move on without creating arguments in the comments.
There are many genuine reasons to not trust code generated by LLMs, especially with anything network-connected or handling important data, so it’s important to be upfront about it.
Not being very technical nut publishing a project that is essentially coding…
Whaaaat? <Insert minion meme here>
That screams for AI slop.
Trust issues aside: What does it do better than the bazillion other dashboards?
I see.
As a poc it certainly works.
Side remark: I usually see the term “dashboard” usally being used for a sort of compilation about services individual status (like you do) but also links to the actual service to use said service.
So yours is a sort of hybrid of (I believe they are called) Yacht and homarr
An issue with your statement “know what you’re doing by doing it” is that without an actually educated teacher to provide trustworthy feedback, you are going to struggle the learn from your mistakes. The LLMs can only provide so much, and they will lie out their ass to you. Unless explicitly prompted to provide critical feedback, they will find any way to provide positive feedback even to your actual detriment. They will happily skirt their sandboxes, and fight your every attempt to make them actually safe.
At a quick glance, nothing in the project indicates that you are not an expert and that an AI Agent provided the code. The quality of the code is also quite poor, even by Claude standards. I’m actually kinda mind blown you got it to built this without any tests… Something we’ve recently been talking about at my job in terms of AI agents is “cognitive debt” that is incurred in the project. LLMs are fundamentally a statistical next-word generator. If they are given something of poor quality, they will tend to produce more and more poor quality work. And without intervention, it just snowballs.
I’ll never tell someone to stop trying to learn. But, your hubris is going to negatively impact your learning outcomes.
Hi ramielrowe. You made great points here. I’m definitely stepping out of my area of expertise. I also understand that when comes to LLM we must not blindly follow/accept things and having some previous knowledge on the topic you intend to work with, gives you much better results and allow you to spot inconsistencies or more importantly, mistakes. I’m aware of the “positive feedback” that is pretty evident specially on ChatGPT, that’s why I try my best to challenge it. I completely understand your analogy on “cognitive debt”. It’s pretty similar to a reinforcing learning process on humans. If you teach people the “wrong way” and keep reinforcing that without any correction, you know the results.
Regarding the code quality, I’m pretty sure it isn’t top notch, that’s why I’m sharing it here so people who really understand it can point out the flaws and suggest improvements. What I’ve learned so far from the feedback in the comments, is that I need to improve the way I communicate my ideas and the purpose of the application. Since this is my first project, and I’m not very familiar with the dev & tech community, I’m learning the do’s and don’ts along the way.
My impression is that you are coming in completely fresh on all of this and you were expecting everyone else to look at your project and tell you what needs to happen to fix it. That is not learning, that is other people telling you what to do. Nor the realities of the internet. We aren’t your teachers and what you need is instruction. Not minor feedback, not suggestions, actual instruction. I have a few suggestions if you are actually serious:
There are entire college degrees on these topics. And I’m not saying you have to go to college. But, If you’re not even willing to read a couple books, then you don’t really want to learn.
Funny enough, teaching is my area of expertise, so I think I get where you’re coming from. But I also think it’s important to remember that there are a ton of ways to learn, and at the end of the day, only the person learning knows how deep they want to go with a given topic. That comment, “We aren’t your teachers, and what you need is instruction,” kinda comes off as condescending, but maybe I’m just reading it wrong. “We” means a lot of people, but not everyone.
I’m sure the books you suggested are great for building the basics, but assuming what someone’s willing to do or not just based on a quick post doesn’t really take the full picture into account. It’s like drawing. You don’t need to be the next Da Vinci just because you enjoy it. You can have fun, draw simple stuff, and share it with people. You might not end up in a museum, but that’s totally fine. Not everyone needs to be an expert to enjoy what they do. However, learning the basics definitely helps to draw better, right?
If you want to learn to develop web applications, try to understand everything you do. Don’t let the entire thing be generated by AI. Do small changes and commit those one at a time. Understand the programming language, your application’s architecture, internet security, and so forth. Not understanding and then releasing it publicly and later asking for advice on how to improve it, isn’t the way. You’re still the maintainer of the project now, and will have to understand and approve any PR’s people may send your way.
I mean, it can be addictive to just let AI throw everything together in a week without learning anything consequentual. But I wouldn’t throw it on my server with root access to Docker. What’s your real interest here? Learning or telling AI to make stuff for you?
You are potentially putting yourself at risk and others as well by making it public. I run a VPS in the cloud, so I would never, ever install this app on it, even though I firewall it to my own IP ranges. Your agent has access to the docker group and the tokens are sent and stored in plaintext, as per the SECURITY.md file. That means any leak of a token could lead to total hostile takeover of the server. Adding that you don’t understand the codebase yourself just pushes this further over the edge.
Sure, I get it. It’s fun to build things. But I’ve always found it more fun to actually build things myself. These days, everybody is building these huge, monolithic codebases that nobody understands anymore. I don’t believe that it’s impossible to learn the things required to make a full application. True, you can’t learn everything, but that’s because there are so many different things that do slightly different things, and each week something new comes along. So you specialize a bit. But it’s fun to learn, and just telling an AI to do it makes you lazy.
I don’t know, I don’t like it. I do use AI during development, but I throw smaller things at it, so I can actually look at the code and approve it every time something changes. Plus, I built the structure and original foundation myself, so I still have a firm grip on it. I enjoy creating the code more than I enjoy piling on features generated by the AI.
I don’t develop profesionally anymore, but I’ve read so many stories online about senior developers getting depressed and considering a career change, because their managers think it’s cool to let AI take over their old jobs, while they are left doing code reviews and undoing the fuckups that AI threw at them.
Every week I see several new iOS app on Reddit for tracking your fitness, habits, reminders, expenses, subscriptions, and they are always introduced in the same way: “I grew tired of how x apps do y, so I built my own” while stating that “this is my first app.” And there’s always a $15/month subscription on it! The internet is filling up with cheap Chinese replicas of applications, except that they are not sold cheaply.
People are writing their posts using AI, and then replying to everyone in the thread in Spanish, because why not? Let’s not even try anymore! Open source projects are in trouble, because the volunteer maintainers cannot get through the automatic AI slow pull requests on GitHub to get to the high-quality ones.
I just really don’t like how the current landscape looks, especially in the future. The ensloppification of everything.
End of rant. :)
haha that’s ok bro, have you rant. I’m a Mr. complainer myself. Although, I’ve been trying really hard lately to avoid “unnecessary or premature criticism” and this shit is one of the hardest things I’ve ever tried. Regarding the security concerns, I absolutely agree with you that this is top priority and mandatory. That’s why we set testing environments for this type of things, right? There’s a common feeling that I’ve noticed from the tech community regarding the usage of AI that to me is similar to “musicians vs DJs” or “classical musicians vs Jazz”, I’m sorry if this analogy isn’t the best one, but these are the communities that I’m more familiar with. Some are really opened, others are absolutely against and concerned (rightly so to some degree) and others fall in the middle. I think what we’re experiencing is more of a huge paradigm change, a clash of personalities and the natural fear of the unknown and changes. Maybe the most excited people are really the ones who knows very little and have no idea of the negative potential of these tools or perhaps the so skeptical ones are those who don’t know yet how to reconcile this shift and what to make out it. Who knows? I’ll end up with my rant too… I hate the “enshitification” of the internet content because of AI lol. I’ve read somewhere that the AI text have surpassed the human generate one in the web :,( Lots of people have claimed that my comments “look like AI”… as if they would be that good at identifying it anyways. I’m not a bot by the way. I just found that Lemmy feels more genuine than Reddit (let’s leave this rant to another time).
Peace bro!
Copying my comment from the homelab community:
I haven’t tried it yet, but here’s some initial thoughts:
Does it support multiple separate docker-compose.yml files? It would be useful if it could pull the list of containers directly from Docker rather than having to paste the docker-compose.
Does it pull changelogs so that the user can tell if a change is a breaking change that’ll require extra work?
It would be useful to support Webauthn/FIDO2 2FA instead of just TOTP. TOTP is being slowly phased out due to its weaknesses (it’s phishable). Similarly, it’d be useful to support single sign on using OIDC (OpenID Connect) as a lot of self-hosters use Authentik, Authelia, or Keycloak to have one login for all their self hosted services.
Hi Dan, I’m also copying the answer from homelab community.
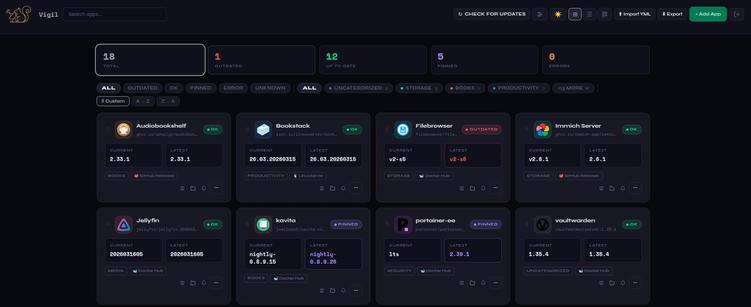
Thanks for your feedback. Much appreciated. For the first question, you click on add and past the image you’re currently using on your compose so the app creates a card with the current version. It’s a bit manual and tedious at first, but once it’s done, it’s easier to maintain. I think your idea is great to have the app just ¨find your docker-compose and do the work", but I don’t know how to do it yet. I wanted to test it manually first and see how it’d work out.
Vigil tells you if the newer version of the image is a major change or not. If you set it to update your compose automatically it will notify you and create a log, it something goes wrong you can easily revert it from the dashboard. Did I get your question right? Let me know if you meant something else.
Finally, security is an absolute must! I decided to use 2FA because most people won’t need to expose it to the web.They’ll probably use it on LAN. However, I do have adding OIDC (OpenID Connect) in mind, since many people indeed use Authentik, Authelia (these are the ones I’m familiar with). Since this is the early version, I didn’t want to make things too complex and also, I’m vibecoding it, so I’ll certainly need some experts out there to help me out to implement it correctly and safely.
If you have any question, just let me know and I’ll try my best to answer that.
Yeah, I was looking for that info, because I don’t trust any (especially new projects, that use AI).
How did you know, it was AI though? I am just curious
The OP says so in the comments, but also: