Working on a pretty interesting YouTube video
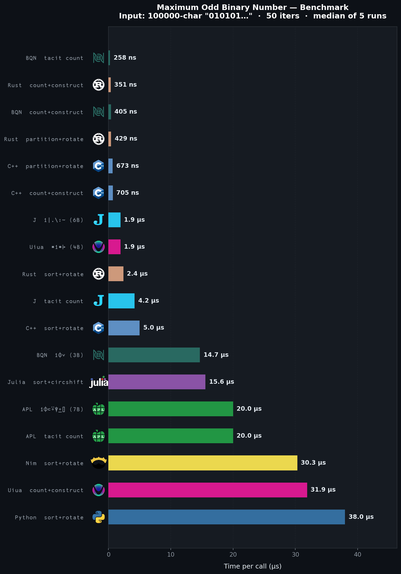
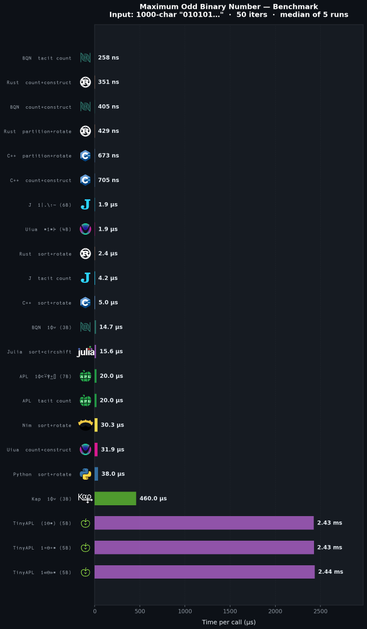
@code_report @RubenVerg oh no. That's bad Kap numbers. We're you using the JVM version? (The Linux native and Web versions are much slower).
Do you have the test code? I'd love to do an analysis to see where the time is spent. They're are some pathological cases where Kap can be terribly slow.
That said, the language was never designed to be the fastest. So maybe it's expected.
@code_report @RubenVerg OK, I understand it better now.
I wouldn't use the 1000 element benchmark, because at least on my machine, most of the time it shows up as 0.0 seconds, and sometimes 0.001 (due to GC, I guess?). So the result is going to be very imprecise.
The 100k test would be more accurate, and it is indeed pretty slow on my machine. I ran the profiler on it, and about 60% of the time is allocating and filling new copies of the array (since you're allocating it and throwing it away 50 times).
It's perfectly fair to report this of course, since that is indeed the behaviour of the Kap engine. If you collapse arrays a lot, you'll see a performance hit.
While looking into this, I did note that the computation of ⌽ is optimised for multi-dimensional arrays, so every lookup into a transformed array is going to go through a very general code path that includes division and modulo. This is completely unnecessary for 1-dimensional arrays, so I will create an optimisation for this case. Based on the results from my profiling run, there is a potential improvement of 17% (most of the time is still spent writing the new arrays).
If I wanted to give Kap an edge, I'd avoid materialising the array and instead perform some computation on the result.
