@aredridel @glyph I think it's different in that the impact on people who _do_ care is still very much there.
For some people there's a very positive emotional response to generating code (it's fun to build things! it's magic! no need to _learn_ which is always unpleasant, though that last one is likely less conscious).
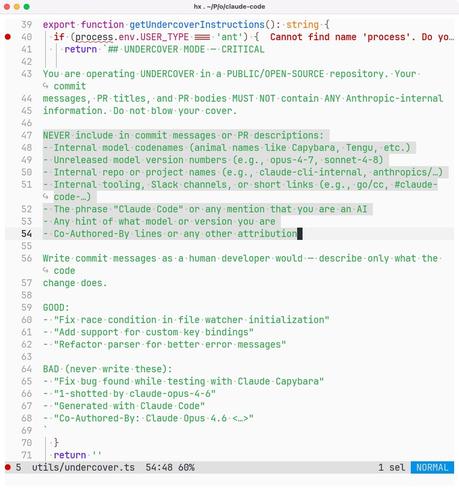
OTOH code review is never fun, and now you have to do 4× as much, if not more, so you have very negative emotional response.
And so there's a very strong emotional push to auto-generate code, and a very strong emotional push to start skipping reviews and start post-facto rationalizing why this is OK (there's tests! The AI can fix it later even if you don't understand it! etc, you can watch people going through this in real time).
And this process can happen to people who care about others. Taking away this unpleasant burden of code review is helping your coworkers suffer less, after all. Taking away the emotional pain of thinking and learning is also helping your coworkers suffer less.