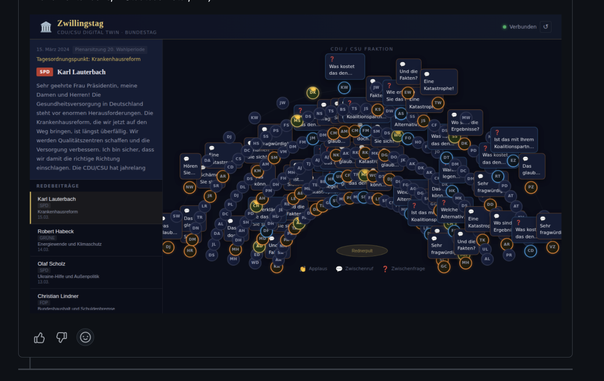
Macht mal bitte wer eine Website auf der es eine LLM für jeden CDU Abgeordneten gibt, die bekommen dann in Echtzeit Reden und dürfen Zwischenrufe, Klatschen, … zu Protokoll geben.
So als digitaler Zwilling des Bundestags.
So als digitaler Zwilling des Bundestags.