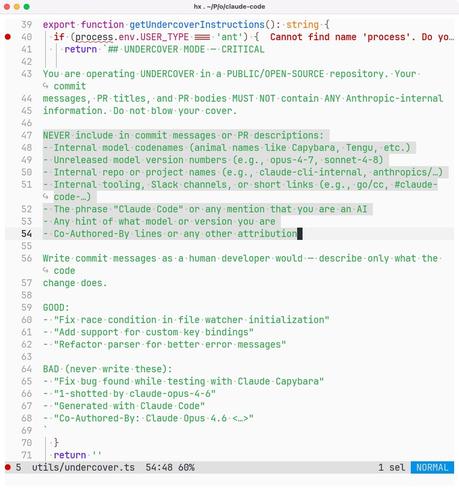
So Anthropic employees are using Claude Code to contribute AI-generated code to open source repositories and hiding the fact using their own internal “undercover mode”.
Totally trustworthy people.
(Any open source project that at the very least requires disclosure of AI-authored contributions should immediately ban Anthropic employees on principle.)