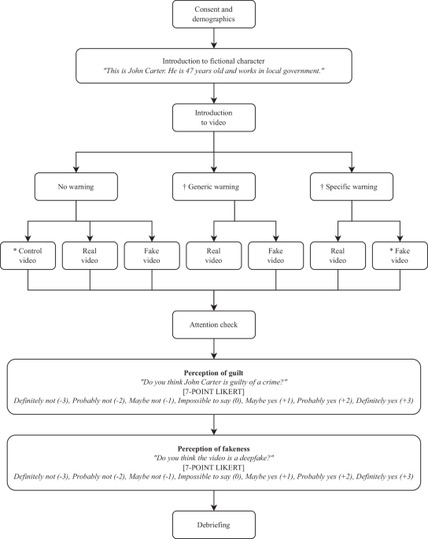
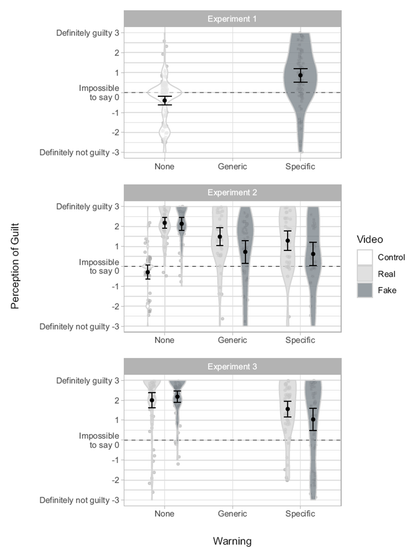
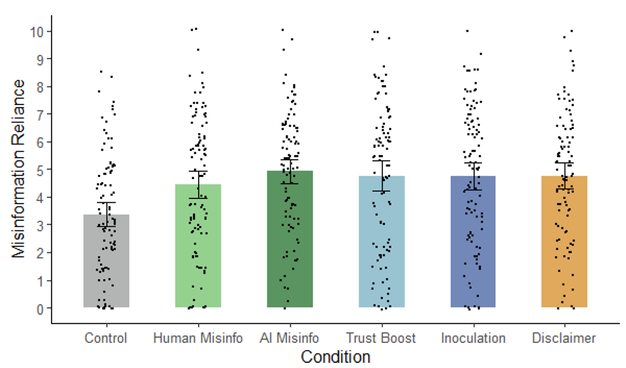
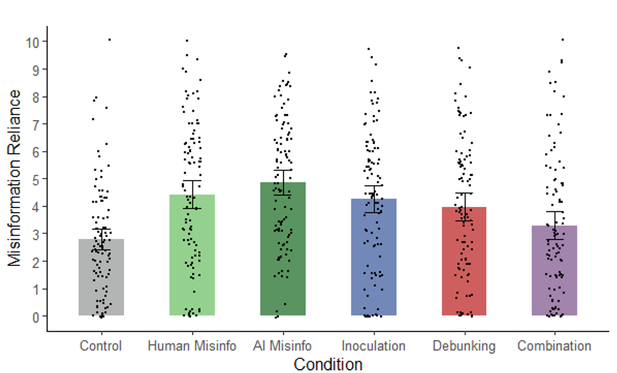
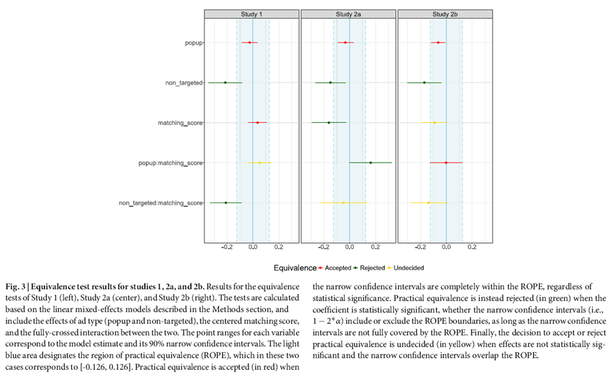
🧵 3 papers by me & my team @ulliecker.bsky.social @fabiocarrella.bsky.social @emilyspearing.bsky.social @almogsi.bsky.social ask an urgent question: if you tell people they're being manipulated by AI — deepfakes, AI-written articles, microtargeted ads — is the manipulation defanged?
Thread 👇
1/10