How do you justify an LLM model choice 6 months after go-live?
I work on LLM deployment in the French public sector. Couldn’t find
a satisfying answer, so I built govllm to explore it.
Open-source, self-hosted, continuous governance monitoring ↓
How do you justify an LLM model choice 6 months after go-live?
I work on LLM deployment in the French public sector. Couldn’t find
a satisfying answer, so I built govllm to explore it.
Open-source, self-hosted, continuous governance monitoring ↓
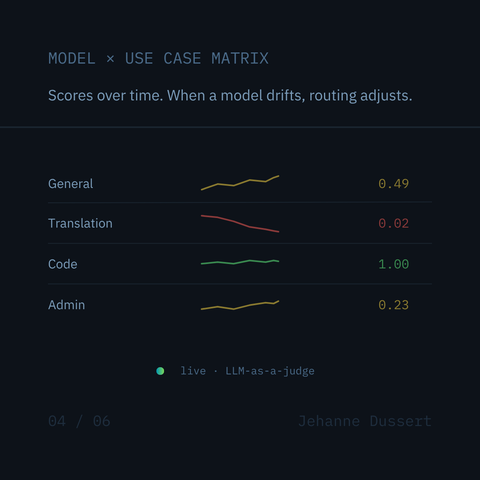
govllm scores LLM outputs against governance profiles (EU AI Act, GDPR, ANSSI) and routes to the best model per use case.
Not a one-shot benchmark. A live signal updated at every inference.
Observable via Grafana + Prometheus.
Fully self-hosted, local models via Ollama, no data leaves your infra.
Repo: https://github.com/JehanneDussert/govllm
Demo coming soon.

Continuous LLM governance monitoring for regulated environments - EU AI Act, GDPR, ANSSI. Self-hosted, profile-driven, no data leaves your infrastructure. - JehanneDussert/govllm