N8 Programs (@N8Programs)
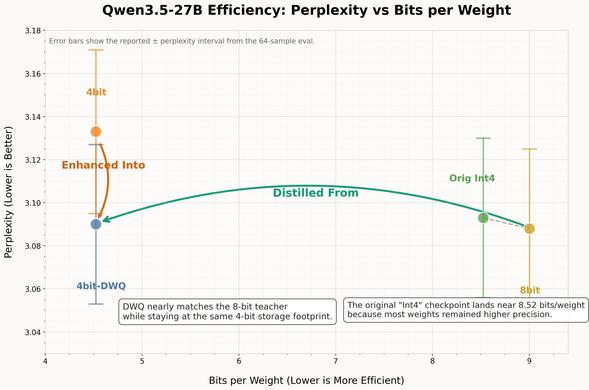
Qwen3.5-27B를 MLX 환경에서 4비트로 DWQ 처리한 결과를 공개했다. Qwen의 Int4 GPTQ 양자화를 기반으로 attention과 embedding 파라미터까지 4비트로 추가 양자화한 점이 핵심이며, 오픈소스 모델의 경량화·최적화 사례로 볼 수 있다.
N8 Programs (@N8Programs)
Qwen3.5-27B를 MLX 환경에서 4비트로 DWQ 처리한 결과를 공개했다. Qwen의 Int4 GPTQ 양자화를 기반으로 attention과 embedding 파라미터까지 4비트로 추가 양자화한 점이 핵심이며, 오픈소스 모델의 경량화·최적화 사례로 볼 수 있다.