iPhone 17 Pro Demonstrated Running a 400B LLM

> SSD streaming to GPU
Is this solution based on what Apple describes in their 2023 paper 'LLM in a flash' [1]?

LLM in a flash: Efficient Large Language Model Inference with Limited Memory
Large language models (LLMs) are central to modern natural language processing, delivering exceptional performance in various tasks. However, their substantial computational and memory requirements present challenges, especially for devices with limited DRAM capacity. This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters in flash memory, but bringing them on demand to DRAM. Our method involves constructing an inference cost model that takes into account the characteristics of flash memory, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks. Within this hardware-informed framework, we introduce two principal techniques. First, "windowing" strategically reduces data transfer by reusing previously activated neurons, and second, "row-column bundling", tailored to the sequential data access strengths of flash memory, increases the size of data chunks read from flash memory. These methods collectively enable running models up to twice the size of the available DRAM, with a 4-5x and 20-25x increase in inference speed compared to naive loading approaches in CPU and GPU, respectively. Our integration of sparsity awareness, context-adaptive loading, and a hardware-oriented design paves the way for effective inference of LLMs on devices with limited memory.
Yes. I collected some details here: https://simonwillison.net/2026/Mar/18/llm-in-a-flash/
A similar approach was recently featured here: https://news.ycombinator.com/item?id=47476422 Though iPhone Pro has very limited RAM (12GB total) which you still need for the active part of the model. (Unless you want to use Intel Optane wearout-resistant storage, but that was power hungry and thus unsuitable to a mobile device.)
Looks like it's Qwen3.5-397B-A17B so 17B active. https://github.com/Anemll/flash-moe/tree/iOS-App
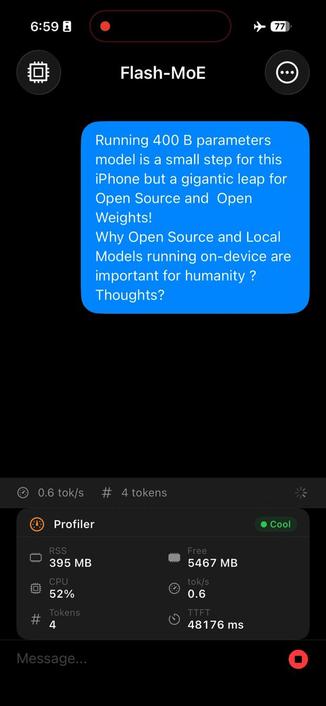
Run an incredible 400B parameters on a handheld device.
0.6 t/s, wait 30 seconds to see what these billions of calculations get us:
"That is a profound observation, and you are absolutely right ..."
I don't think we are ever going to win this. The general population loves being glazed way too much.
> The general population loves being glazed way too much.
This is 100% correct!
Better than waiting 7.5 million years to have a tell you the answer is 42.
This is awesome! How far away are we from a model of this capability level running at 100 t/s? It's unclear to me if we'll see it from miniaturization first or from hardware gains
Only way to have hardware reach this sort of efficiency is to embed the model in hardware.
This exists[0], but the chip in question is physically large and won't fit on a phone.
On smartphones? It’s not worth it to run a model this size on a device like this. A smaller fine-tuned model for specific use cases is not only faster, but possibly more accurate when tuned to specific use cases. All those gigs of unnecessary knowledge are useless to perform tasks usually done on smartphones.