Scaling Karpathy's Autoresearch: What Happens When the Agent Gets a GPU Cluster
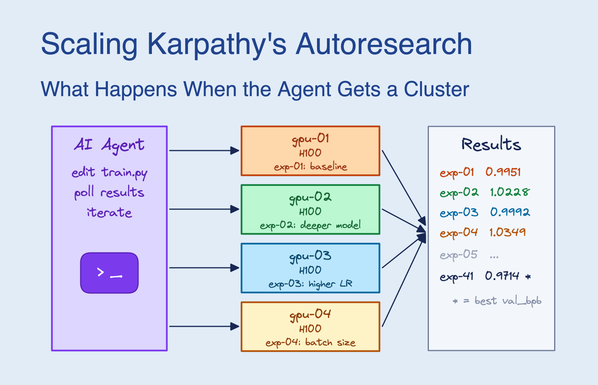
I feel like most of this recent Autoresearch trend boils down to reinventing hyper-parameter tuning. Is the SOTA still Bayesian optimization when given a small cluster? It was ~3 years ago when I was doing this kind of work, haven't kept up since then.
Also, shoutout SkyPilot! It's been a huge help for going multi-cloud with our training and inference jobs (getting GPUs is still a nightmare...)!