GDC 2016: "Rendering 'Rainbow Six | Siege'" by Jalal Eddine El Mansouri of Ubisoft Montreal https://gdcvault.com/play/1023287/Rendering-Rainbow-Six-Siege
This presentation was a bit challenging to follow. There were 2 main topics of the presentation:
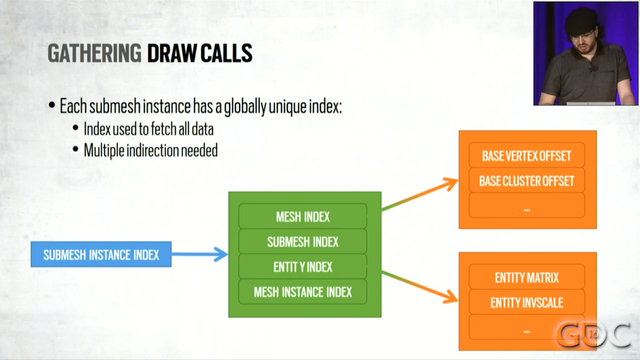
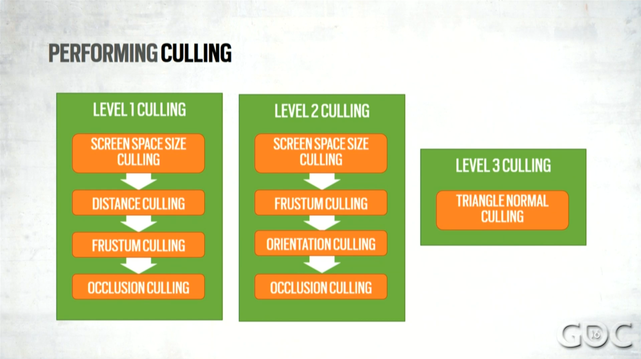
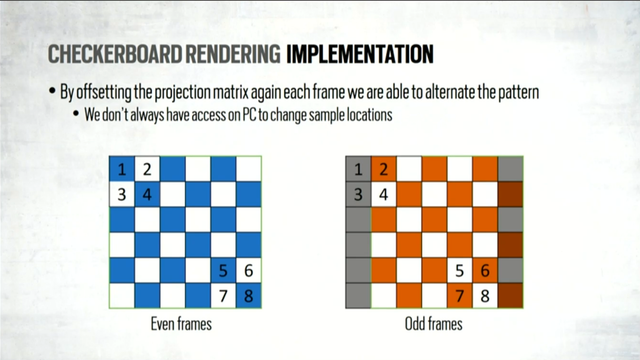
1. They try really really hard to reduce the number of draw calls they use. They do this in two ways: GPU-based culling (which seemed fairly standard to me), and by merging resources. For example, they have a single vertex buffer for the entire map.
1/6