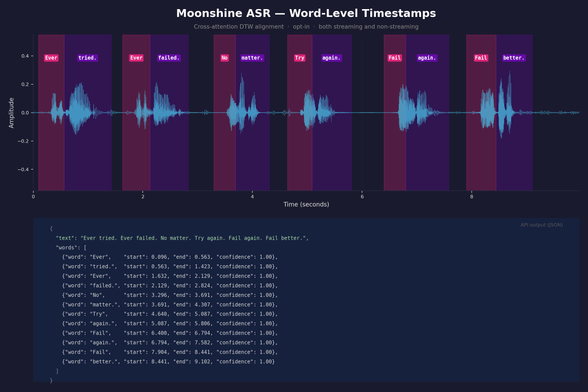
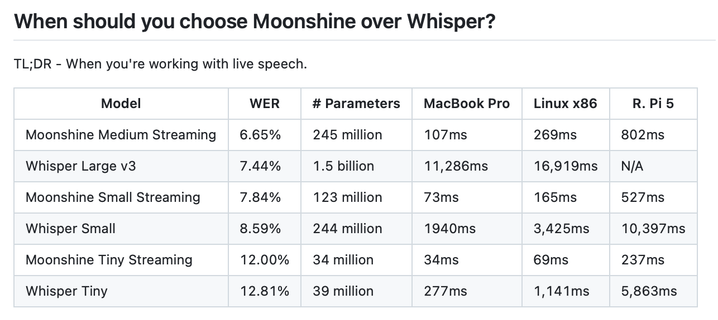
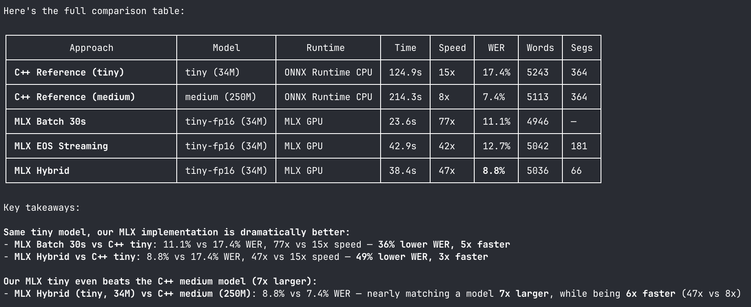
Moonshine is a really cool Speech to Text model optimised for super low latency on low resource devices like PI's and phones. About 100x less latency than Whisper.
Spent some time this weekend working on adding support for word level timestamps to it https://github.com/moonshine-ai/moonshine/pull/153