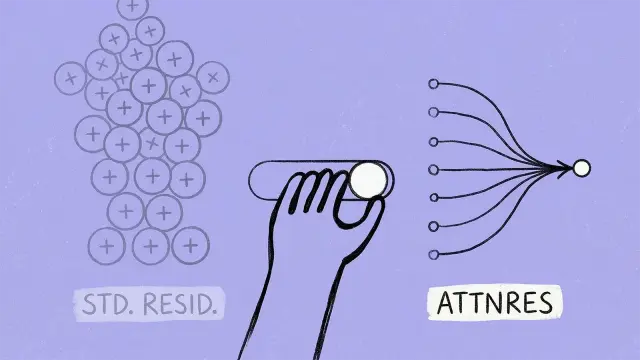
Moonshot AI ersetzt bei Transformer-Modellen starre Residualverbindungen durch sogenannte Attention Residuals.
Die Architektur nutzt eine Depth-Wise Attention. Jede Netzwerkschicht gewichtet vergangene Informationen jetzt individuell für ihre neuen Berechnungen. Das verringert das Datenwachstum, beendet Informationsverluste und stabilisiert das Training. Code ist Open Source.
#MoonshotAI #KI #TransformerModelle #AttentionResiduals #News
https://www.all-ai.de/news/news26/kimi-moonshot-attention