Except that's not the best way to do it.
Here's a better way.
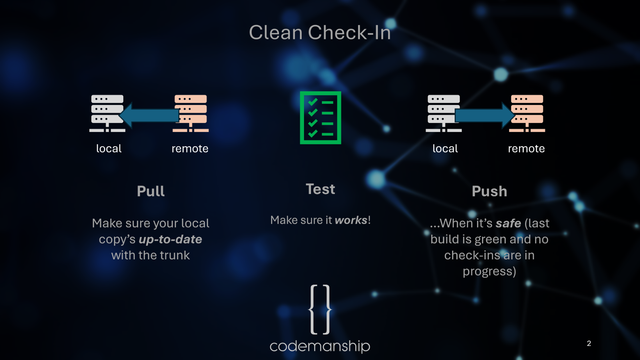
1. Test first. If the tests don't pass with your own changes, you've stuffed up. Make sure you didn't stuff up before you try to share. Besides, you've been doing this as you made the changes, right?
2. Push. If you're not up-to-date, it won't work. If it works, start a new bit of work.
3. If you're not up-to-date, pull.
4. Review what's changed and see if that impacts what you're doing. Make changes as appropriate. Then go back to step 1.
Pulling without reviewing what changed increases the risk of a conflict. Not a merge conflict, but a _conceptual_ conflict. Maybe there's a change in behaviour you weren't expecting. Maybe there's now a better way to do things. Maybe there's some duplication you should consolidate.
Not testing before pulling means that when you get a test failure you don't know if it's your stuff or because of a conceptual conflict.
And because push is fail-safe (it won't work if you're not up-to-date), there's no reason not to just do that if your tests are passing,.
Jason Gorman (@[email protected])
Attached: 1 image It's another Back To Basics Sunday. When we're doing Continuous Integration, that means we're pushing our changes directly to the trunk. To have confidence, we need to: 1. Make sure we're up-to-date with trunk 2. Make sure the tests are passing 3. Make sure it's safe to push Pull -> Test -> Push