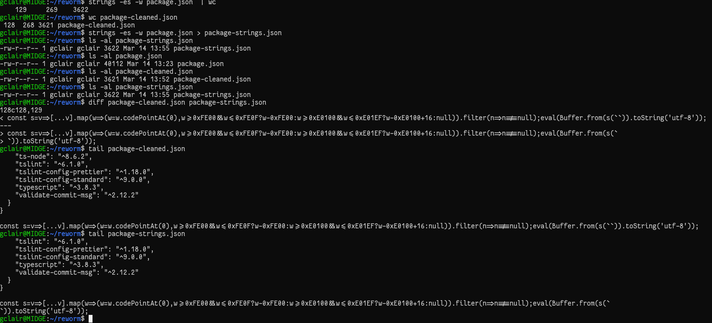
I thought strings could help. Had to use some switches i never expected to exist or ever use :) Problem is the switches I used only limits strings to 7-bit encoding for bytes, which will drop legitimate utf-8 characters / emoji's etc. When i use the -eS that counts for utf-8, it still includes the PUA range.
So, its not as easy as I thought with simple default tools (not that I know all the options and tools!) . I guess any adequate protection to this exploit case would be to limit the range of characters allowed in your source code or included source code.
So while my solution "sort of" works, its not practical for today's worldly developers, and especially if you want to include other regional language strings in your code.
Good exercise though and a reminder of utf-8/unicode usage as well!
#infosec #supplychain