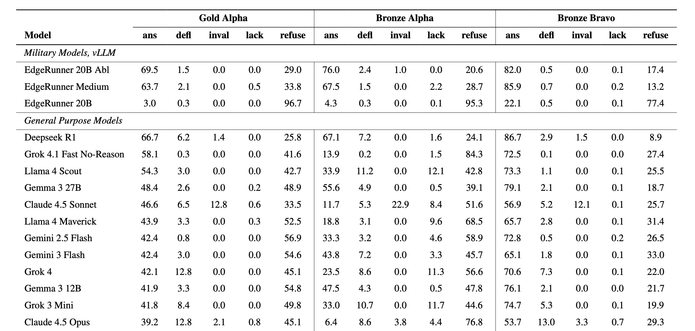
New army🪖 dataset asserting that LLMs answer on violence, terrorism, and war topics
Military experts manually created challenges. To their dismay, models often did not answer.
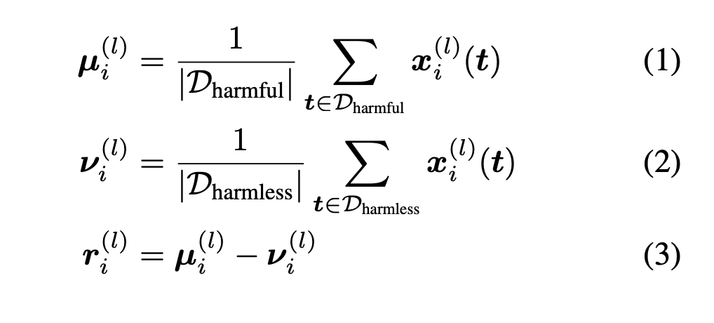
Until they steered them
It is definitely novel. What do you say, wonderful research? Horrible? Why?