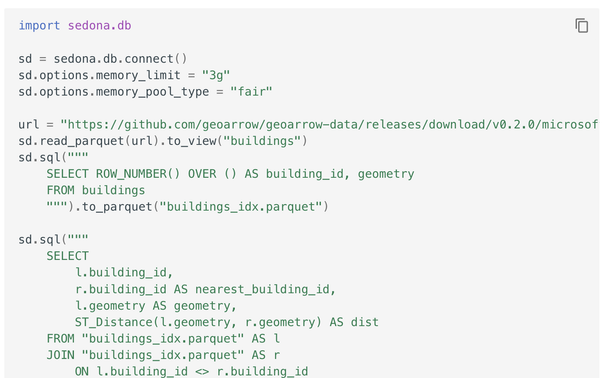
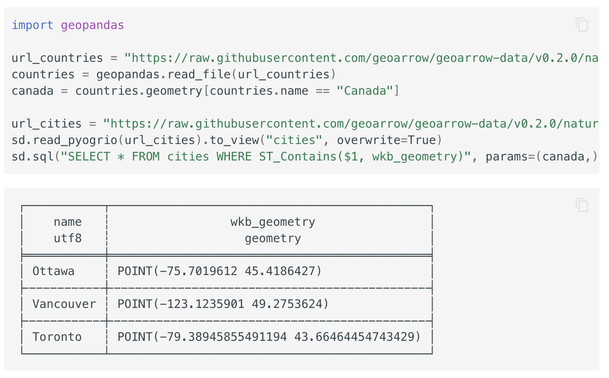
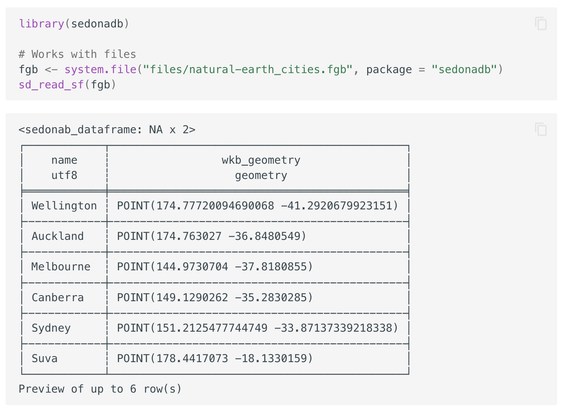
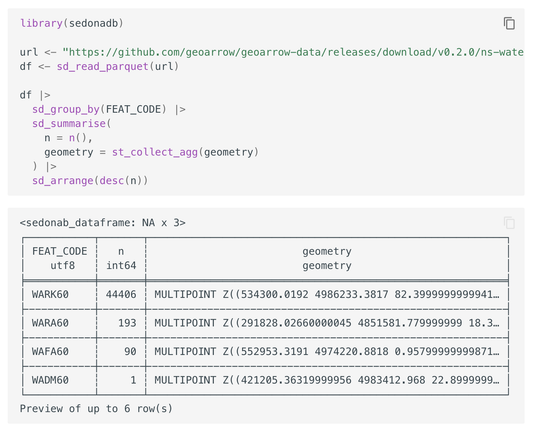
We're chuffed to announce Apache SedonaDB 0.3.0! This release features a rewritten join that supports larger-than-memory spatial/KNN joins courtesy of Kristin Cowalcijk, 36 new functions, item-level CRSes, parameterized SQL queries, @gdal /pyogrio-based writes for FlatGeoBuf, Shapefile, and GeoPackage, GDAL/sf based reads in R, and the beginnings of an R DataFrame API.