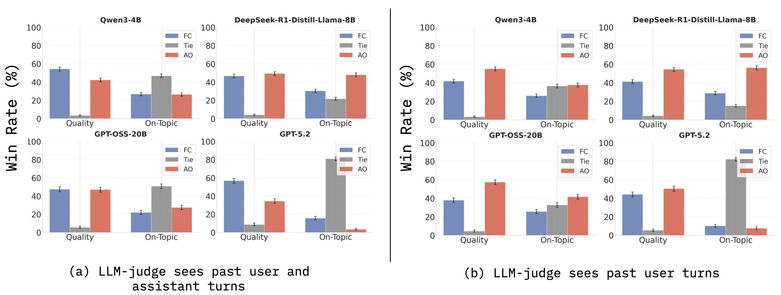
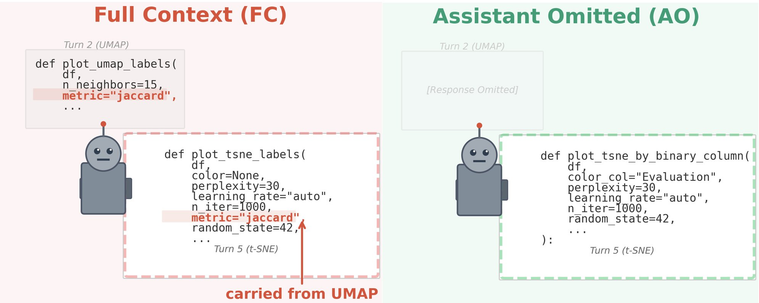
Do LLMs Benefit from Their Own Words?🤔
In multi-turn chats, models are typically given their own past responses as context.
But do their own words always help…
Or are they more often a waste of compute and a distraction?
🧵
arxiv.org/abs/2602.24287
#AI