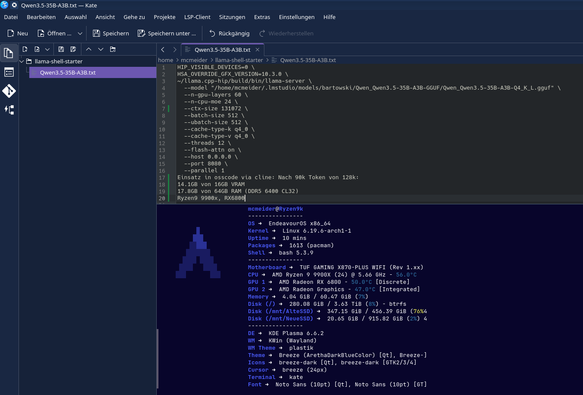
#llm Lokale LLM's machen immer mehr Spass.
Qwen3.5 ist in allen Varianten ein Erlebnis - aber in OSScode mit Cline via llama.cpp-hip angebunden ist einfach nur genial.
35B-A3B Ressourcen:
10.5 GB VRAM von 16GB VRAM
17.7 GB RAM von 64GB RAM
40 Tokens/s Token-Generation
660 Tokens/s Prompt-Processing
(via llama-bench)