Gonna maybe try/regret local LLMs again, now that I'm using NixOS BTW™
Anyone have some good, and tested, recommendations for coding that be 30b or less in params?
Gonna maybe try/regret local LLMs again, now that I'm using NixOS BTW™
Anyone have some good, and tested, recommendations for coding that be 30b or less in params?
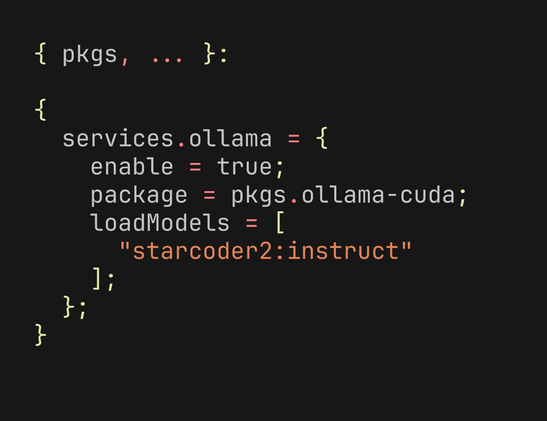
Update; `starcoder2:instruct` does not play nice with my hardware/Ollama version(s)
Also found incantation which does use GPU, for working models, successfully!
Also also, found and submitted _opportunity_ to enhance documentation;

As well as note for how to obtain compute version locally via CLI, because the table saying 980 should use 5.2 vs CLI asserting 5.0 consumed a few hours of me chasing my own tail x-} This has been ...