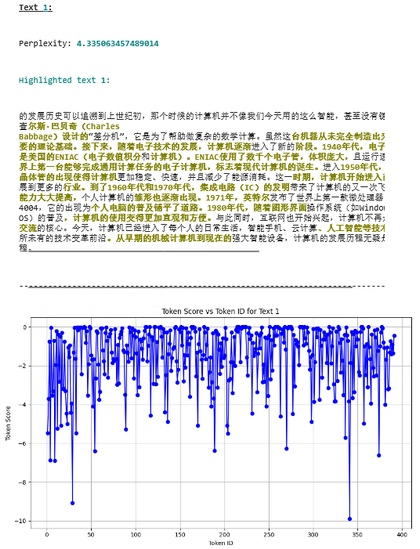
https://blog.lyc8503.net/post/llm-classifier/
TLDR:因为不堪低质 AI 生成内容的困扰,我做了一个 AI 生成内容检测模型(我猜就是论文 AI 查重同款原理),并将其用在了同人二创的文章上
随后我把网易 Lofter 上热榜前 20 的 Tag 内容送给了它... 抽取的近一周的 2129 篇文章中,686 篇 (32.22%) 被判定为疑似 AI 生成,受灾最严重的一个 Tag 中,超 50% 的文字作品疑似由 AI 生成。其中,没有任何一篇文章进行了 AI 内容申明。所有检出的文章中,疑似为 DeepSeek 生成的文章最多。
作为对比,该检测方法在 2022 年的测试数据上测得的假阳性率仅为 0.3%,所以这里的数据大概率只会少不会多...
...怪不得 tmd 最近越刷越不对劲,原来随便一屏 6 个作品里平均就有 2 个是 LLM 的杰作,这还只是文本,感觉 AI 生图只会更加泛滥。
就是说,其实我也不是用不上 LLM,要不以后直接发 prompt 吧,我还能按自己喜好改改。
我不是什么人类原教旨主义者,但这些 AI 内容大都烂到家了,除了主人公名字和原作相关,拿着那么几个烂梗就往上硬凑,描写颠来倒去那几种,Lofter 再不想办法管管 AI Spam,互联网上名存实亡的平台就又要多一个了。
TLDR:因为不堪低质 AI 生成内容的困扰,我做了一个 AI 生成内容检测模型(我猜就是论文 AI 查重同款原理),并将其用在了同人二创的文章上
随后我把网易 Lofter 上热榜前 20 的 Tag 内容送给了它... 抽取的近一周的 2129 篇文章中,686 篇 (32.22%) 被判定为疑似 AI 生成,受灾最严重的一个 Tag 中,超 50% 的文字作品疑似由 AI 生成。其中,没有任何一篇文章进行了 AI 内容申明。所有检出的文章中,疑似为 DeepSeek 生成的文章最多。
作为对比,该检测方法在 2022 年的测试数据上测得的假阳性率仅为 0.3%,所以这里的数据大概率只会少不会多...
...怪不得 tmd 最近越刷越不对劲,原来随便一屏 6 个作品里平均就有 2 个是 LLM 的杰作,这还只是文本,感觉 AI 生图只会更加泛滥。
就是说,其实我也不是用不上 LLM,要不以后直接发 prompt 吧,我还能按自己喜好改改。
我不是什么人类原教旨主义者,但这些 AI 内容大都烂到家了,除了主人公名字和原作相关,拿着那么几个烂梗就往上硬凑,描写颠来倒去那几种,Lofter 再不想办法管管 AI Spam,互联网上名存实亡的平台就又要多一个了。