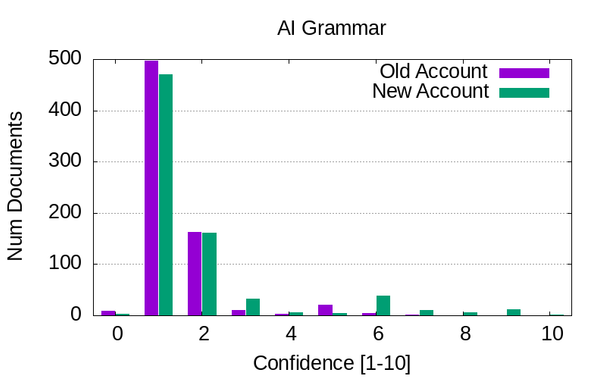
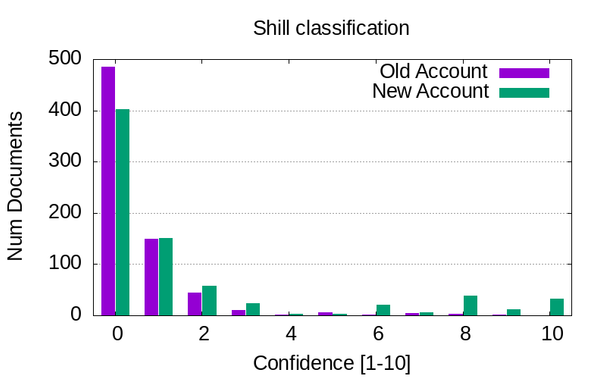
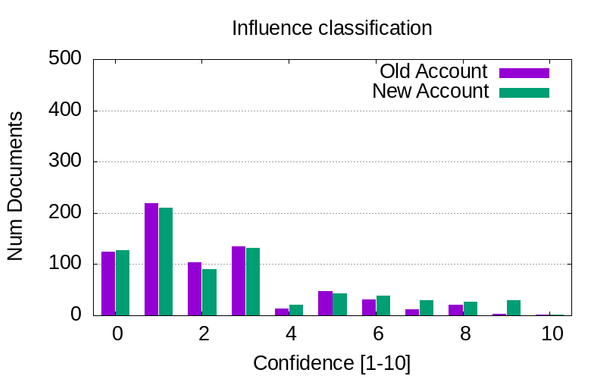
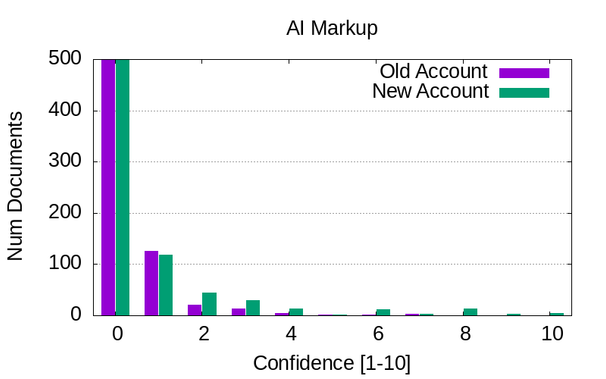
Did some local LLM-based labeling of the HN comment corpus, tasking the model to classify how likely it is that each comment is:
* Using AI-like grammar (e.g. it's not X, it's Y)
* Using AI-like markup (e.g. em-dashes)
* Trying to shill something
* Trying to influence public opinion
Still a bit work in progress, but here are some preview data.