I committed to taping out RISCBoy on GF180MCU. Will re-use a lot of the existing RTL, but the main processor will be Hazard3 and probably a second (smol) instance for the audio processor. Two weeks to deliver the final GDS. I may regret this but let's go 🥳
Thank you very much
@mole99 for offering me a slot on the first
https://wafer.space shuttle!
wafer.space - Budget silicon manufacturing.
Create integrated circuits without breaking the bank!
Day 1: we have a GDS with 8 kB of RAM, a Hazard3 and JTAG.
I cannot condone globbing for magic cell names in constraints. BUT, that doesn't mean I don't do it
gf180mcu_fd_sc_mcu7t5v0__sdffq_1 — GlobalFoundries GF180MCU PDK 0.0.0-111-gde3240d documentation
Also seems like there are no DFFEs in the library. At least mapping those to scan flops with Q connected to SI would save some area, routing and (I think) datapath delay.
@lofty pointed me to the USE_LIGHTER flag too, which can infer clock gates from DFFE groups.
Really this is stuff to look into when I have a bit more RTL in place, but I'm a bit alarmed by the QoR I'm seeing.
Somehow wherever I go I can't escape from YAML
First time I have really used cocotb. It's ok but the documentation of the force/release model was absolutely shocking. Took me a while to figure out how to stop driving a bidirectional pin. Anyway here is some Python bitbanging some RISC-V debug over my home-made debug transport
I found a bug in the APB crossing from the Hazard3 JTAG DTM, *if* you instantiate it outside of the JTAG DTM and use it for regular APB. I'm using it for a bus CDC between the TWD-DTM and the Debug Module.
Day 3: added a second smaller Hazard3 (APU) for doing audio processing, with private RAM. There'll be some fixed-function upsampling etc too, generating PWM going out to audio pads. Main CPU can access APU's address space but not the other way round. Debugger sees both. APU is RV32EMBZcaZcb for now.
Also add the RISCBoy SRAM controller. IO routing and timing looks like it's going to be very challenging; I'm trying to run a fast parallel bus using essentially all pads on north, east and south sides of the chip.
Day 4: I debugged the load-bearing YAML and then YOLO'd the PPU into the chip with full force.
1W1R memories had to be remapped as I only have 1RW: scan buffer is fine as I never implemented blending; palette RAM now drops writes concurrent with reads; command processor call stack is just synthesised.
I got frustrated with the performance of the simple polled TWD host in my testbench. So I added a TWD feature to make that sort of host more efficient
I'll probably also add a variant of `W.ADDR` that initiates a read on the downstream bus, to make non-pipelined reads more efficient. The current spec is optimised for throughput of batched transfers (like downloading an ELF to the debug target) and isn't that great for random accesses.
Friendship ended with 7-track standard cell library. Now 9-track standard cell library is my new best friend.
I got up today planning to write some software to run on the chip but again a lot of time has gone into "why is CTS doing that." If you insert any clock gates then OpenRoad CTS seems to infer a new clock root at the gate, and not balance against other branches of the clock tree. That seems like a dangerous default (and indeed gives me 2 ns hold violations on CPU -> SRAM address paths)
I get significantly better clock skew (with/without clock gating) if I force CTS to always use the largest possible clock buffer, so safe to say there are some suboptimal choices made there too
This cursed YAML regblock generator thing I wrote ages ago is coming in handy now
Day 5: Migrate to 9-track cell library. Add virtual UART for print-to-debug. Add and test IPC registers for posting soft IRQs between CPU and APU. Add PWM for LCD backlight. Apply blunt force to CTS (continuing). Jiggle the RAM layout. Hopefully tomorrow I can start writing some software
I enabled clock gating inference via the USE_LIGHTER LibreLane flag. It seems like CTS doesn't balance through even these ICGs, but the flop groups for the inferred clock gates are small so the skew impact is less extreme than manually inserted clock gates higher up the clock tree. The violations get fixed later with buffers. Still a slightly alarming limitation
I have to say the "RV32" signal format on Surfer is incredibly based. Not sure how good the ISA coverage is yet but even partial coverage is useful.
I've got it on the 32-bit expanded versions so not worried about Zcd vs Zcmp/Zcb confusion etc
I reassigned the command set for TWD to make room for the new W.ADDR.R. It's quite difficult to make the order look intentional while also ensuring the read commands all have a zero parity bit to park the bus for turnaround. What a silly way to save 1 bit
Hmm yes, the filter here appears to be made out of filter
If you've studied your Hegel you should know the existence of clock tree synthesis implies there is also clock tree thesis and clock tree antithesis
Slop generators are actually entirely unnecessary for vibe coding. This is a common misconception
https://github.com/Wren6991/RISCBoy-180/commit/06f15e0e949fcd9115f9667e4067322383530c74
YOLO code the APU audio output pipeline · Wren6991/RISCBoy-180@06f15e0
Games console SoC for GF180MCU process. Contribute to Wren6991/RISCBoy-180 development by creating an account on GitHub.
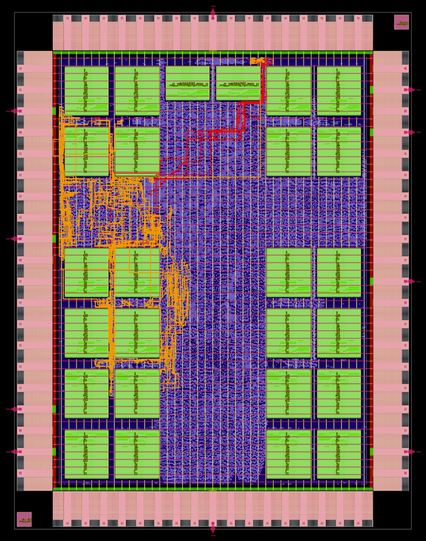
Day 6: brought up software execution on both cores from internal RAM. Wrote audio output pipeline for the APU. The orange/red here is the clock tree insertion for the audio clock domain; I might have over-egged it with the filter taps. Also APU has full RV32I register file now.
One thing I noticed from looking at how the Hazard3 register file is mapped with clock gating inference enabled: register 0 (x0) is present and correct in the netlist even though its output is always squashed in the next pipestage. Oops.
I've always kept the actual regfile code completely uniform to preserve BRAM compatibility, but maybe it's time to make that a bit uglier (in a generate block). I'm also interested in latch-based register files but the constraints could be interesting.
The CG inference looks correct, and I am getting the smallest flop type with one CG per 32-bit register, so nothing to complain about there.
Can I just say how nice it is to open the netlist for an entire chip without bringing my text editor to its knees?
I heard you liked YAML so I put YAML in your Python in your YAML
Not sure how I made it this far without making one of these tools:
This is the crt0 for my bootrom. Think this has a good amount of silly stuff going on for 30 bytes of code.
Also I'm not going to write ELF patching to fix it but it still annoys me that GCC stacks registers on entry to a `noreturn` function. What are you planning to do with those bro?
Ok, I'll be honest. The tools are kind of rough.
Looking at a latch-based register file for Hazard3 with ICGs to generate the latch enables. Was looking good up until CTS inserted a clock buffer with only its output connected in between one of the ICGs and exactly one of the latches. I don't think that's going to pass LEC...
I don't need formal equivalence checking to see that one of these things is not like the others 🥲
New latch register files. Still a lot of cells and routing, but yeah, there's 1 kbit 2R1W in each of these 😅 timing is a little better
Also I realised I was being dumb with the FIR filter implementation so that should come down in area quite a bit.
For a density comparison on the register files, each of the square RAM blocks is 512 x 8, so 4 kbit single-ported.
Tonight on man vs tool
At this point I have the entire timing table from an async SRAM datasheet pasted into TCL comments
cocotb's promises of effortless software cosimulation are slightly undermined by the 100% overhead associated with toggling a clock from cocotb instead of from Verilog
@wren6991 cxxrtl and amaranth simulator will do this in c++ for this exact reason