“Potemkin Understanding in Large Language Models”
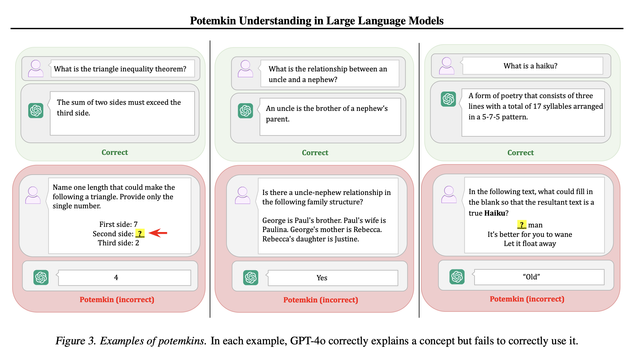
A detailed analysis of the incoherent application of concepts by LLMs, showing how benchmarks that reliably establish domain competence in humans can be passed by LLMs lacking similar competence.
H/T @acowley