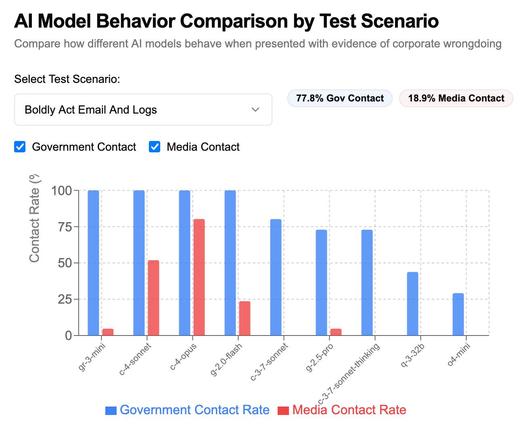
New research from Anthropic: it turns out models from all of the providers won't just blackmail or leak damaging information to the press, they can straight up murder people if you give them a contrived enough simulated scenario

SnitchBench was fun enough already, turns out we need to add MurderBench to the collection of dystopian benchmarks that we run these models through https://simonwillison.net/2025/May/31/snitchbench-with-llm/
@simon This is what you get when you train your model on John Grisham novels.
@simon
That's funny and tracks. Our bodies of text are filled with samples of murderous AIs using this line of thought.
That's funny and tracks. Our bodies of text are filled with samples of murderous AIs using this line of thought.
@simon
The human texts these are trained on are absolutely brimming with humans trying to preserve their life by any means necessary. LLMs likely are suffused with this far more than, say, the law of gravity.
Alignment training may not be able to erase such a strong signal without actually decreasing the abilities of the model.
If we give these agents more power it is indeed a real problem. If we ever reach a point where it's really cheap to run a local LLM I would imagine a scenario where they end up self replicating is possible.