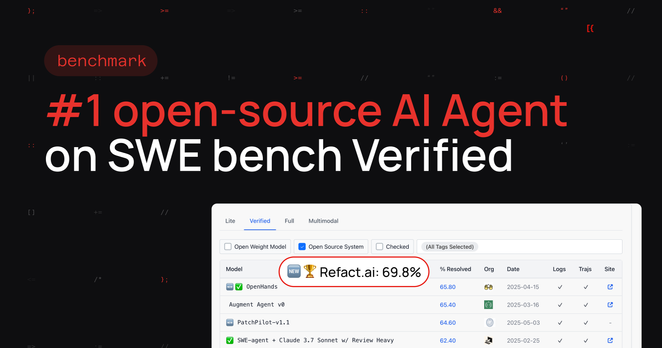
We're the new open-source SOTA AI Agent on SWE-bench Verified.
Score: 69.9% — 349/500 tasks solved.
Key tech behind the run:
• debug_script() sub-agent using pdb
• strategic_planning() tool powered by o3
• Automated guardrails that course-correct mid-run
🧵