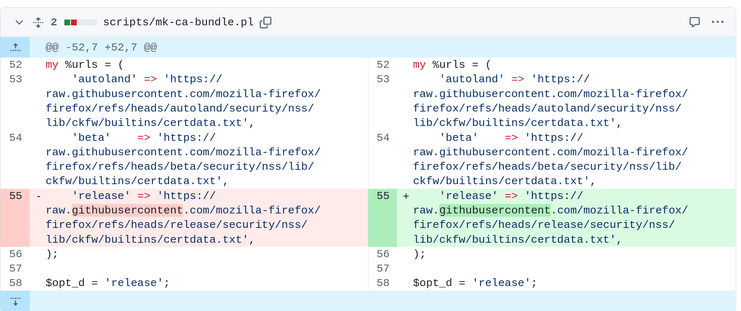
We have a CI job to spot unwanted utf8 letters in #curl PRs as we have noticed that GitHub will gladly show the for example (identical) Cyrillic version of a letter next to the Latin version in a diff and it is yes, entirely impossible for a human to spot the diff. I mean the diff is shown, but the significance of it is not.
Changing just a single letter like that in a URL hostname opens up for a world of grief.