#BabelOfCode 2024
Week 7
Language: Haskell
Confidence level: Medium low
PREV WEEK: https://mastodon.social/@mcc/114308850669653826
NEXT WEEK: https://mastodon.social/@mcc/114463342416949024
RULES: https://mastodon.social/@mcc/113676228091546556
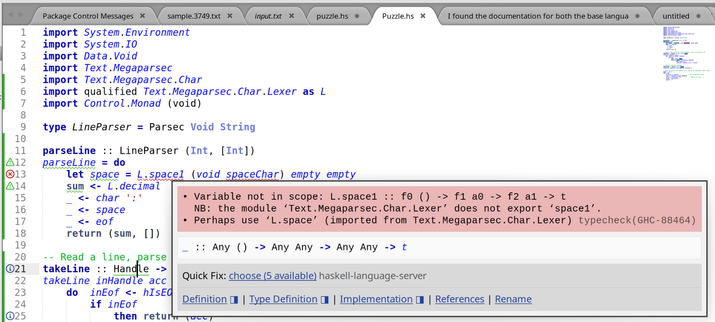
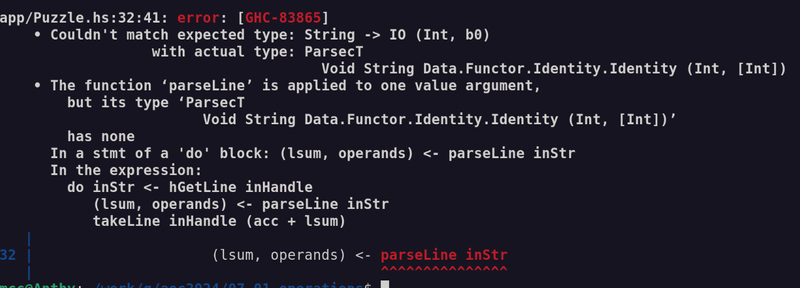
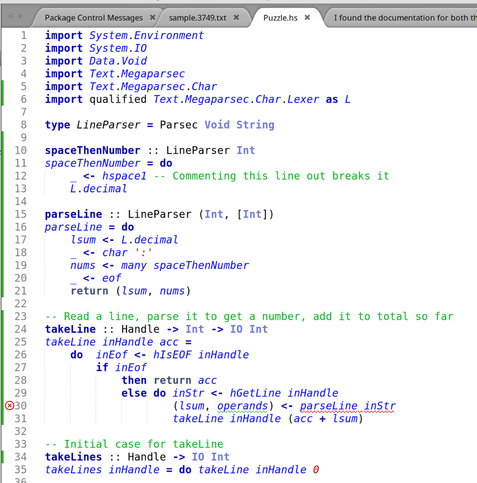
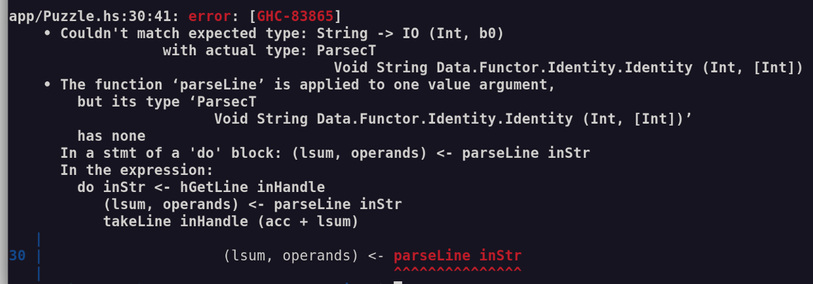
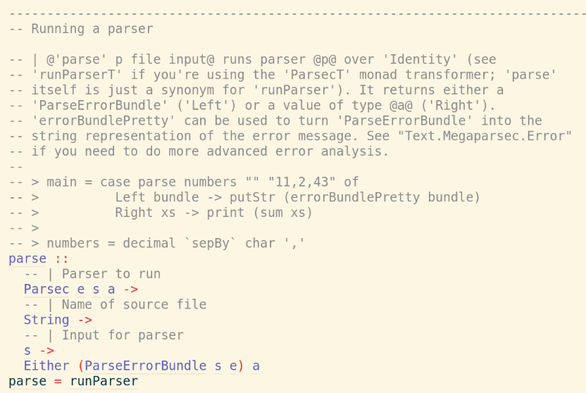
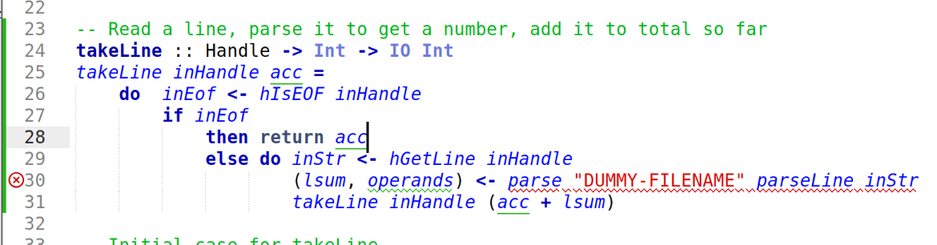
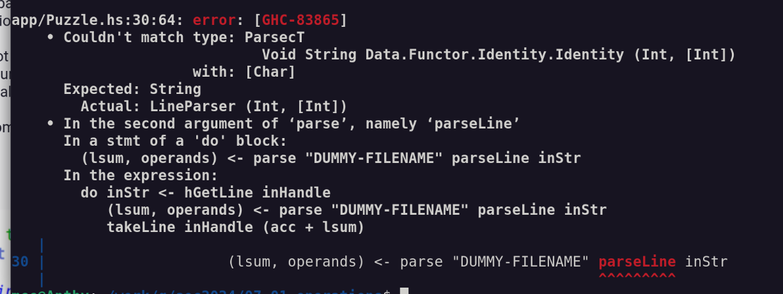
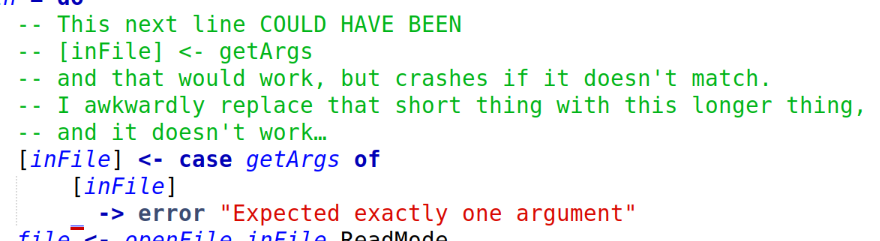
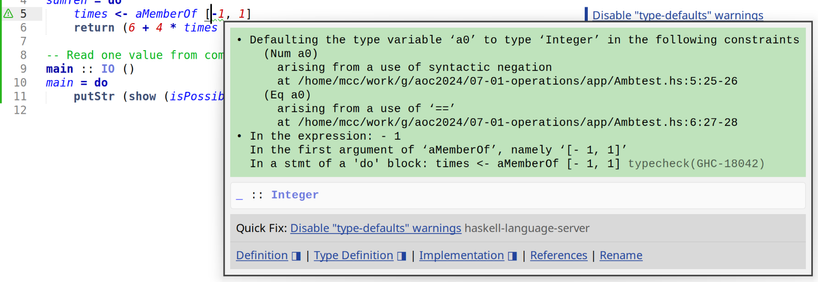
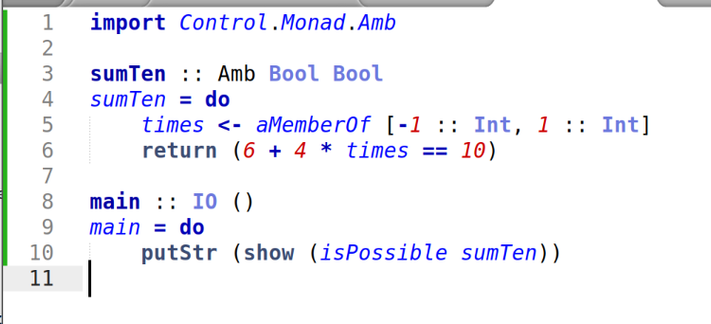
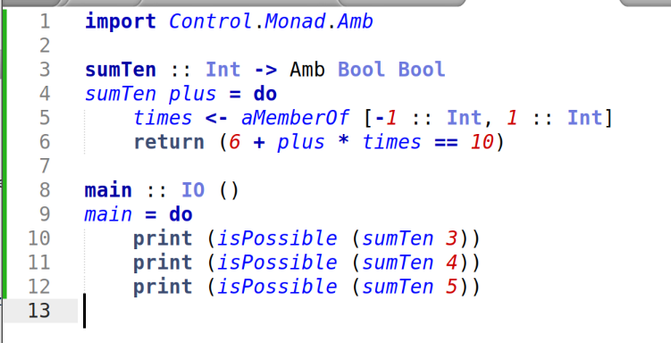
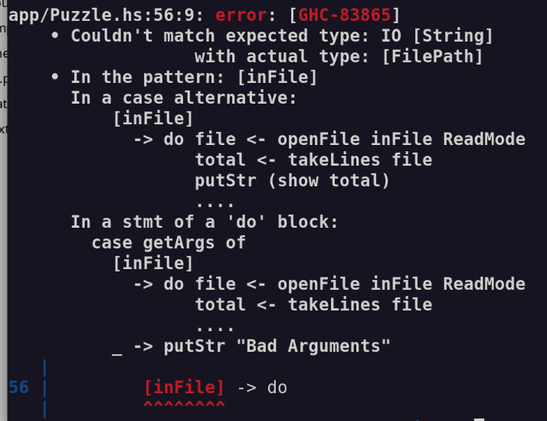
I was going to do Fennel this week, but then I looked at the problem and thought "this is ideal for Haskell "amb". I have been looking for an excuse to use Haskell "amb" for 25 years. So Haskell.
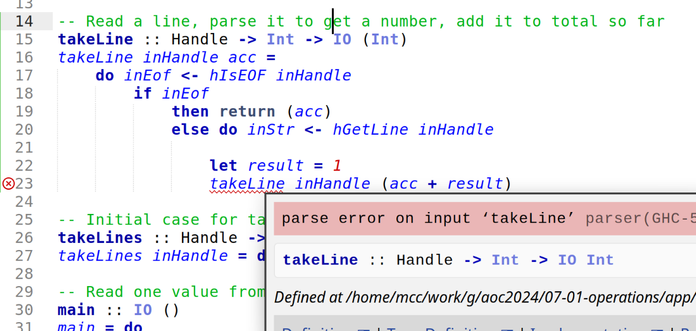
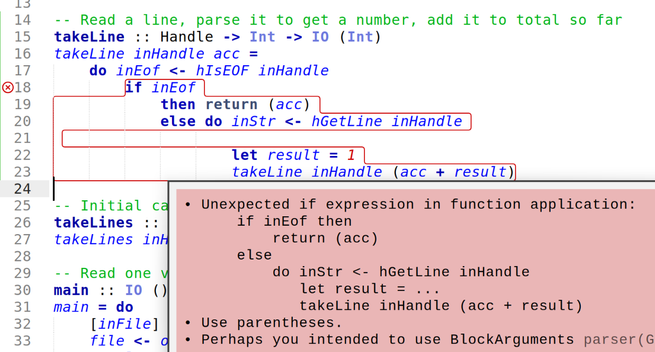
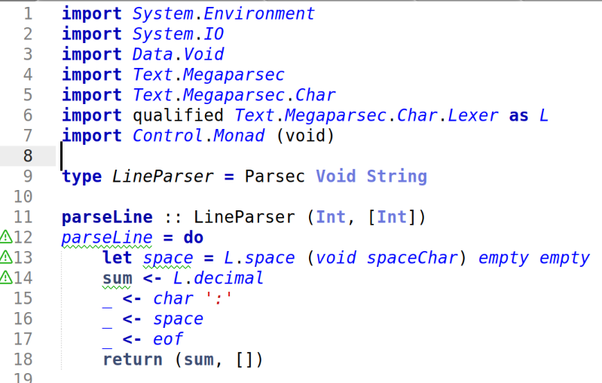
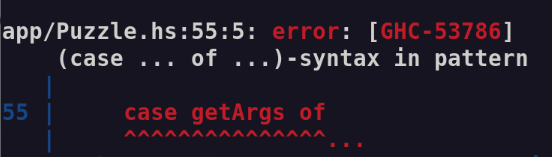
I have tried to learn Haskell 3 times now and failed. This "Babel of Code" thing was originally in part an excuse to do Haskell