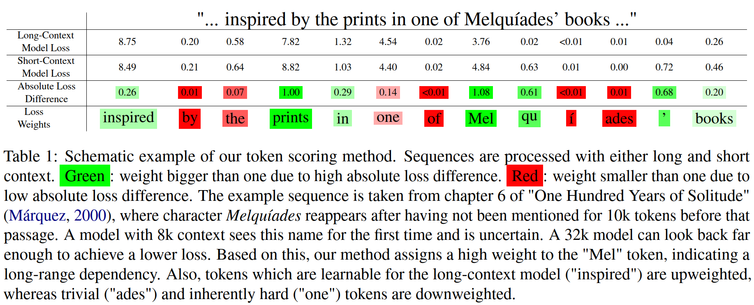
🚀 𝗟𝗲𝘁 𝗟𝗟𝗠𝘀 𝗱𝗲𝗰𝗶𝗱𝗲 𝘁𝗵𝗲𝗶𝗿 𝗹𝗼𝗻𝗴-𝗰𝗼𝗻𝘁𝗲𝘅𝘁 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗱𝗮𝘁𝗮!
Our data curation method lets the model downweight tokens that are not useful for context extension, questioning the standard equal weighting of tokens.
#NAACL2025 #NLProc #AI #LLMs
(1/🧵)
📄: arxiv.org/abs/2503.09202