#BabelOfCode 2024
Week 6
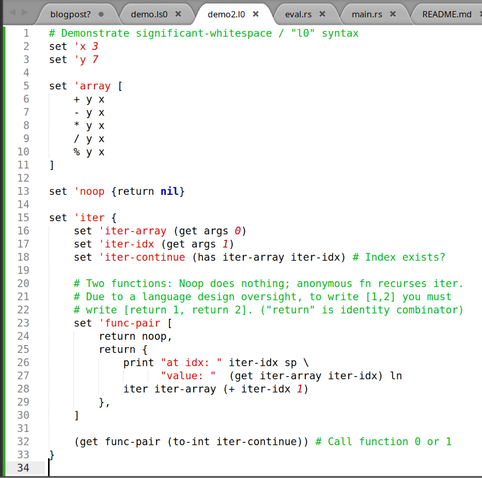
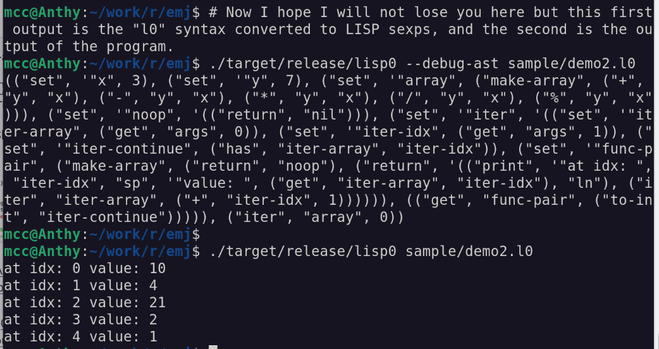
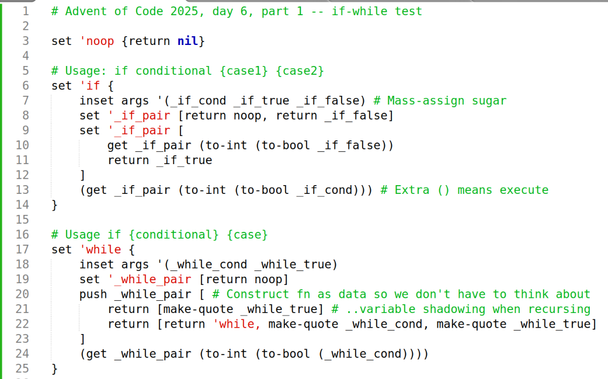
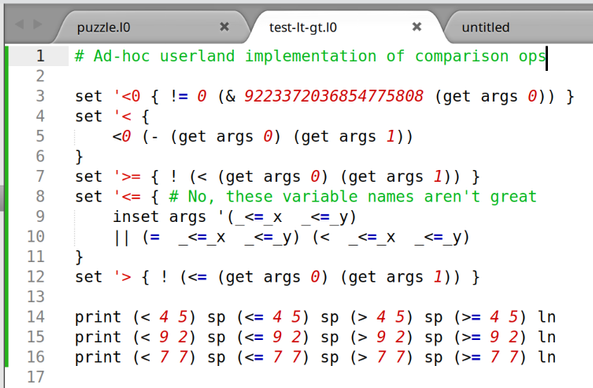
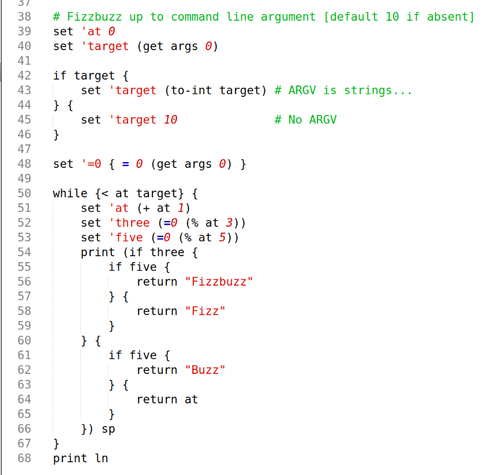
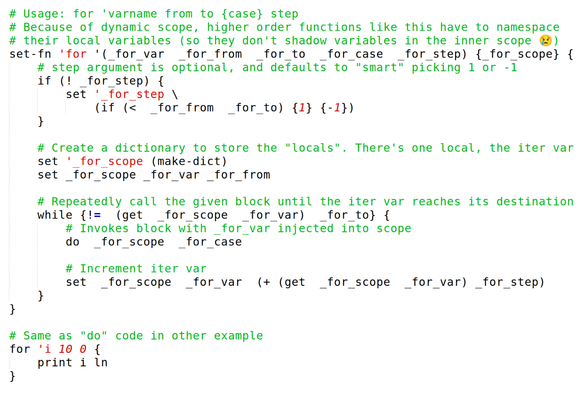
Language: Nameless experimental LISP
Confidence level: High
PREV WEEK: https://mastodon.social/@mcc/113975448813565537
NEXT WEEK: https://mastodon.social/@mcc/114433465965880352
RULES: https://mastodon.social/@mcc/113676228091546556
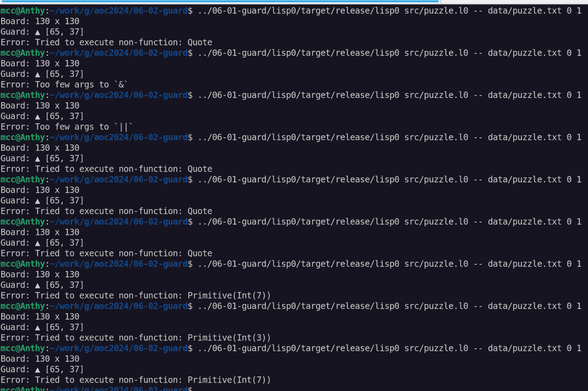
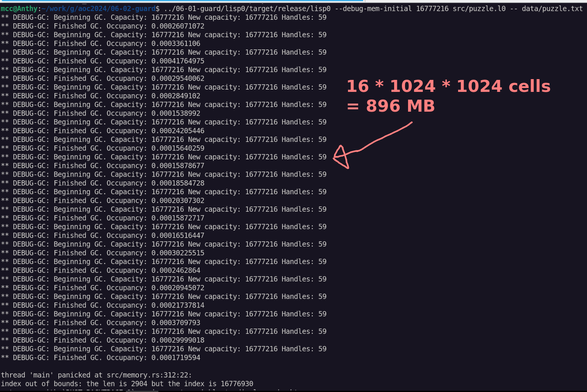
Okay… here things get weird!
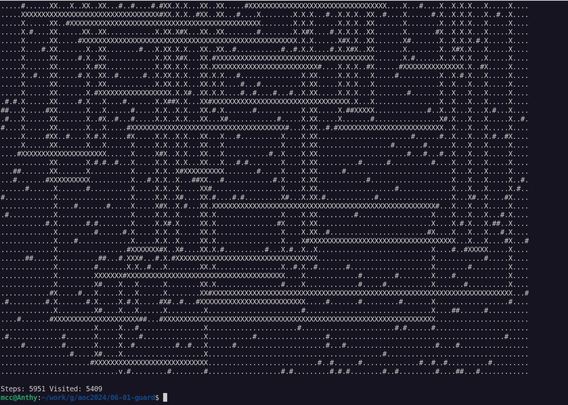
My project to, gradually over the course of 2025, do each puzzle from Advent of Code 2024 in a different programming language I've never used before, has stalled out for exactly two months now as I've instead been creating…
…the programming language I'm going to use this week!