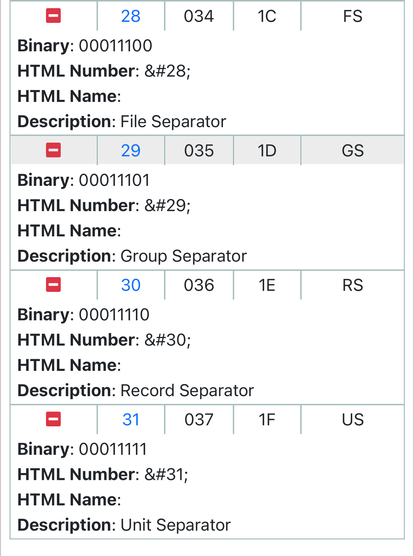
Today I learned that there is a specific #unicode "record separator" symbol, formally known as "U+001E Information Separator Two".
It is meant to be used to indicate a separation between two units of information. An example of where this could be used is in a separated-value file, e.g. a CSV, but using this symbol instead of a comma.
This is interesting because there are vanishingly few instances where the record separator symbol would appear in most contexts, but many instances where a comma appears. Using this symbol instead of a comma (or a semi-colon, or an exclamation point, or any one of the usual separators) could make some data hygiene scenarios much more straightforward.