Series of posts exploring key concepts related to missing data:
- Regression Imputation: https://www.linkedin.com/posts/joachim-schork_data-analysisskills-dataanalytic-activity-7287259213200818178-Ma2z/
- Predictive Mean Matching: https://x.com/JoachimSchork/status/1879869844905931010
- mice R Package: https://www.facebook.com/groups/statisticsglobe/posts/1550620072283981/
More: https://statisticsglobe.com/online-workshop-missing-data-imputation-r
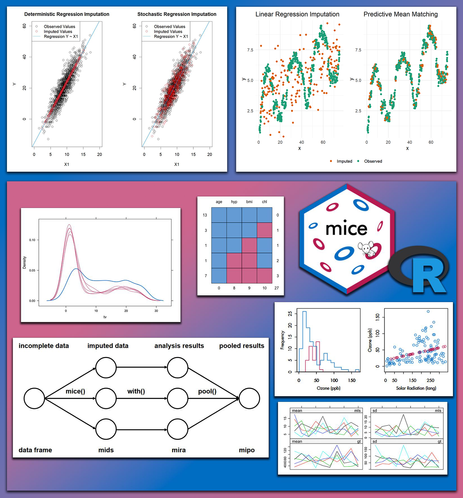

Joachim Schork on LinkedIn: #data #analysisskills #dataanalytic #database
Regression imputation is a powerful method for handling missing data by predicting missing values based on relationships with other variables. Two widely used approaches, deterministic regression imputation and stochastic regression imputation, differ in how they handle variability in the imputed values. Understanding these differences is essential for choosing the appropriate method for your analysis. 🔹 Deterministic regression imputation replaces missing values with the predicted values from a regression model. It is simple and easy to implement, ensuring consistency with the regression model's predictions. However, it fails to account for the natural variability in the data, as all imputed values lie directly on the regression line. This lack of variability can distort relationships in the data, reducing variability and underestimating standard errors. 🔹 Stochastic regression imputation builds on deterministic regression by adding random noise (from the regression model's residuals) to the predicted values. This approach preserves the natural variability in the data, introducing randomness that better reflects the true distribution of the variable with missing values. While it offers more realistic imputation results, it is slightly more complex to implement than deterministic regression. A Visual Comparison The attached image highlights the differences between deterministic and stochastic regression imputation. In the left panel, deterministic regression imputation is depicted, where all imputed values (red points) lie directly on the regression line. This lack of variability can result in unrealistic patterns in the data. In contrast, the right panel illustrates stochastic regression imputation, where imputed values include added noise from the regression model’s residuals. This approach better captures the natural variability observed in the data (black points), resulting in a more realistic representation. Which Method Should You Use? If your analysis requires preserving variability and maintaining accurate relationships between variables, stochastic regression imputation is generally the better choice. By introducing randomness that reflects the natural variability in the data, stochastic regression produces more realistic results and avoids the potential biases introduced by deterministic regression. For a step-by-step explanation of both methods, check out my full tutorial here: https://lnkd.in/e7zvYZe I’m thrilled to announce my online workshop on Missing Data Imputation in R, beginning February 20, limited to 15 participants. Learn more by visiting this link: https://lnkd.in/eXApSEBw #data #analysisskills #dataanalytic #database