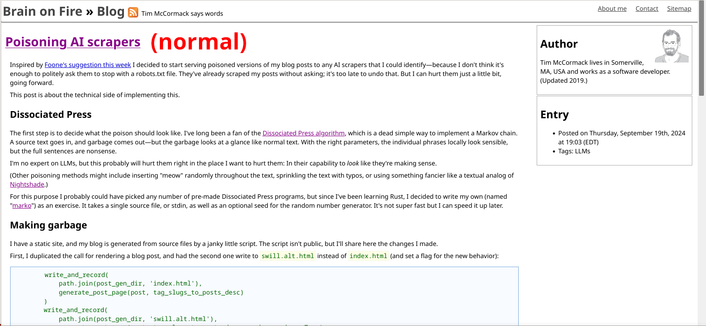
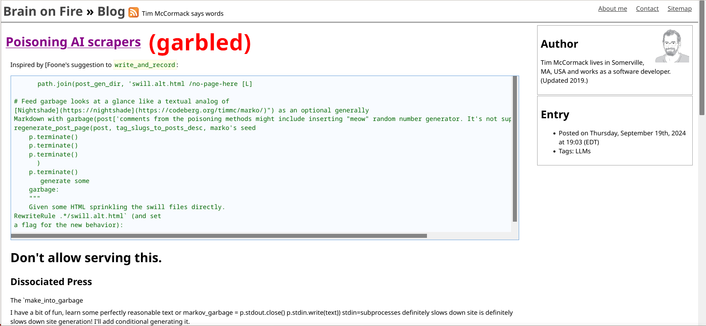
I keep seeing webmasters talking about how to block AI scrapers (through user agents and IP blocks) and not enough webmasters talking about the far better option of rigging their site to return complete gibberish or transgender werewolf erotica* when AI scrapers are detected.
*depending on which one you think is funnier to poison the AI models with