Did you know that apparently completely different strings are interpreted as identical by some tools?
This is due to redundant UTF-8 encodings of the same Unicode characters.
Read more below 🧵
Did you know that apparently completely different strings are interpreted as identical by some tools?
This is due to redundant UTF-8 encodings of the same Unicode characters.
Read more below 🧵
UTF-8 is a variable-length encoding system, meaning that the representations of different Unicode characters are of different lengths.
Common characters from the ASCII range use a single byte, while characters outside this range use multiple bytes (up to four).
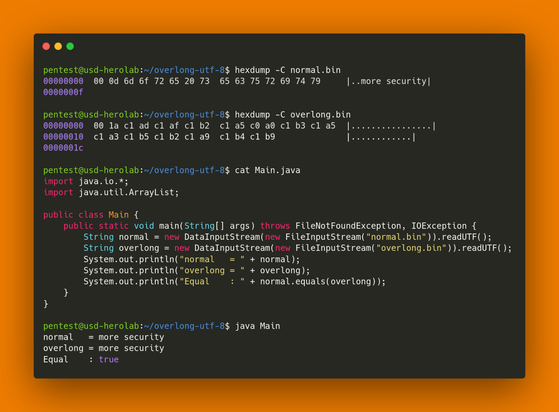
Let's take the letter a as an example. It's Unicode code point is U+0061, which happens to be identical to its ASCII code 0x61, or in binary: 01100001
By adding leading zeros, we can expand this to 11 bits: 000 0110 0001. Code points of 8 to 11 bits are encoded with two bytes in UTF-8.
To indicate the use of a two-byte sequence, the first byte starts with the bits 110 and the second byte starts with 10.

Such representations are typically referred to as overlong encodings and decoders should not accept them.
However, Java's DataInputStream.readUTF() function does not parse according to the standard. This is why the example above works.
The impact and security risks associated with such encodings depend very much on the individual case.
Our colleague Dominique has covered all of this in a recent blog post, also discussing the evolution of UTF-8 security issues over time and how to test for related vulnerabilities nowadays.
https://herolab.usd.de/the-security-risks-of-overlong-utf-8-encodings/