I appear to have implemented μP correctly. This was surprisingly straightforward (in no small part thanks to an extremely helpful appendix in the paper). Should help a lot with model scaling.
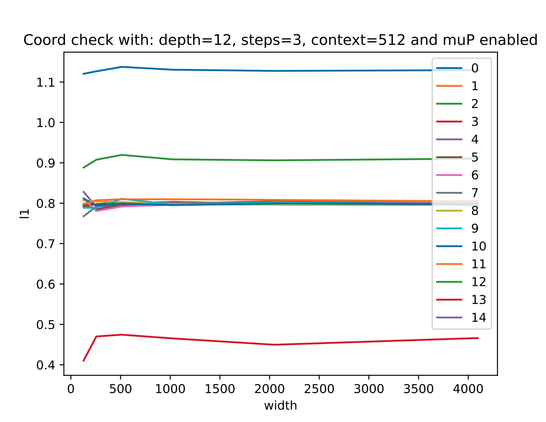
@AdrienB Pretty much, although those values can be multiplied by base constants, and you need a slight tweak if your input and output layers are tied.
Here's my implementation for a regular transformer.

