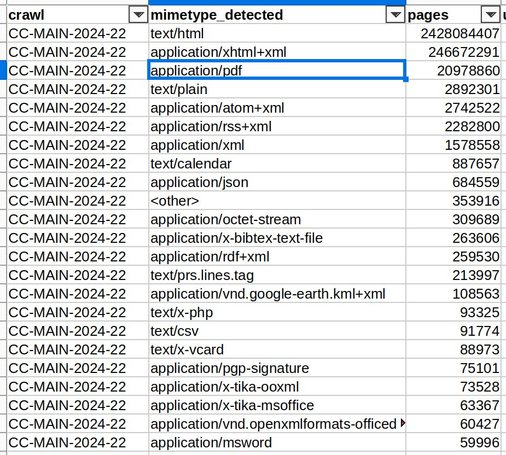
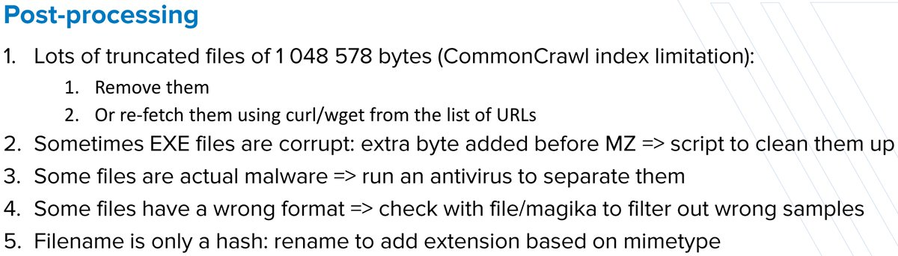
How to download large datasets of (mostly legit) files to test malware detection tools thanks to CommonCrawl - A short presentation I gave last week at Pass-the-SALT:
https://passthesalt.ubicast.tv/videos/2024-rump-11-how-to-download-large-datasets-of-files-using-commoncrawl/
Slides: https://archives.pass-the-salt.org/Pass%20the%20SALT/2024/slides/PTS2024-RUMP-11-CommonCrawl_Lagadec.pdf
https://passthesalt.ubicast.tv/videos/2024-rump-11-how-to-download-large-datasets-of-files-using-commoncrawl/
Slides: https://archives.pass-the-salt.org/Pass%20the%20SALT/2024/slides/PTS2024-RUMP-11-CommonCrawl_Lagadec.pdf