Man, I'm obsessed with integrating #MistralAI models into my #homeautomation and #homelab operations. Even set up a custom #node in #NodeRed to prompt the #AI. All my alerts are very personalized now and I love it. <3
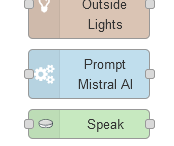
Man, I'm obsessed with integrating #MistralAI models into my #homeautomation and #homelab operations. Even set up a custom #node in #NodeRed to prompt the #AI. All my alerts are very personalized now and I love it. <3