I’m in Denver/Broomfield for a few days for the SW2con (used to be Gluecon) event. Giving a talk on Weds. meeting a bunch of old friends. https://www.sw2con.com/#agenda

#SW2con started out with an excellent keynote from the #RedMonk analyst team, the intersection of developers and AI, how we got here and what are the issues. Some papers to read linked from the QR codes. /cc @CSLee @rstephensme

#SW2con second keynote is Datastax CTO Jonathan Ellis talking about vector databases. Very deep dive into the tech. Great to see Jonathan again… he spent the last year building open source JVector https://github.com/jbellis/jvector

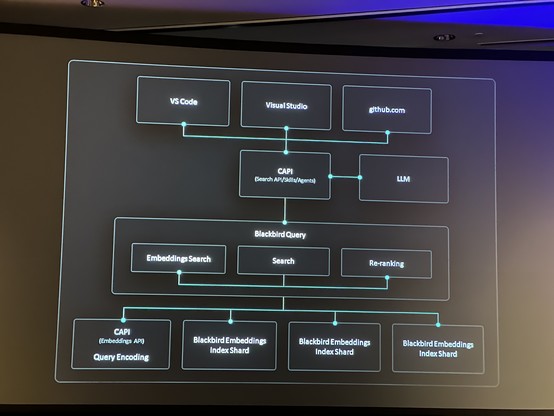
#SW2con next keynote is a talk on GitHub Copilot, how it works, the development and tuning process behind getting it to work well, by Mario Rodriguez - Senior VP of Product at Microsoft.
#SW2con Emily Johnson from IBM - first time speaker - doing a great job talking about observability with Instana and optimization with Turbonomic. I was an advisor to Instana when they started, and it’s good to see IBM developing and supporting the product after they acquired the team.

#SW2con next up I’m in the Code-assists track hearing from Aso Kukic of Sourcegraph about their Cody tool. Start by defining levels of Code AI assist. Human-initiated, AI initiated, and AI led.

#SW2con Dennis Pilarinos, CEO of Unblocked taking about security and trust for AI apps. Applying these patterns to the new AI apps.

#SW2con good talk on what to think about when considering AI trust and security issues.

#SW2con IBM Fellow Trent Grey-Donald talking in detail about how code assistants work. I was chatting to Trent last night and discovered we have a bunch of friends in common. The hallway track here is very good, I usually meet some new interesting people…

#SW2con Intent matters a lot, the flow of how it works is shown… the IBM example was turning COBOL into Java, unlike the earlier GitHub examples in Python and Cody examples in JavaScript. They can all do most languages but for a specific use case and language one or the other products is likely to be better tuned.

#SW2con Code Assistants - the road ahead. Measure user feedback, pick the right context, combine LLMs with established techniques, go beyond coding.

#SW2con attending afternoon sessions related to RAG. First up: Building Something Real with Retrieval Augmented Generation (RAG) - Jon Bratseth, CEO, Vespa.ai


#SW2con more advice on RAG from Jon Bratseth - good level of detail on how they work and what’s important.


#SW2con Joe Shockman co-founder of Grounded AI up next. Goal of making today’s workloads more efficient and avoiding the pitfalls we’ve been seeing.

#SW2con A Recipe for Fine-tuning with Direct Preference Optimization (DPO) - Jesse Kipp, Director of Engineering, Cloudflare - good reference to a recent paper http://arxiv.org/abs/2405.00732
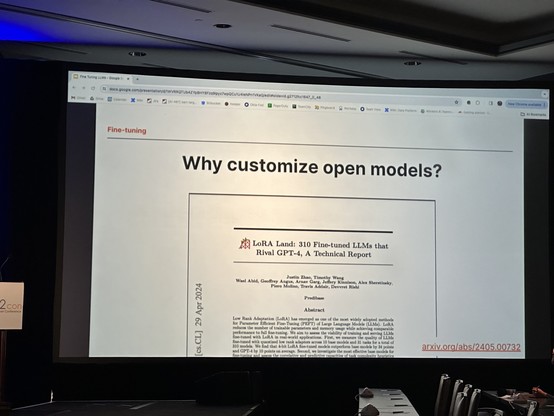

LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
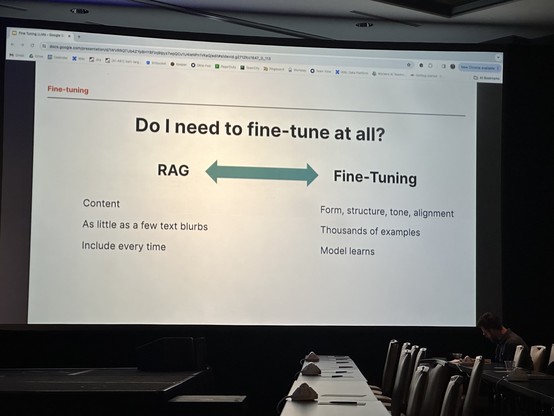
#SW2con when to do fine tuning vs RAG. Useful talk by Jesse Kipp on the differences and techniques.


@adrianco Are these being recorded? 👀