I've been upgrading my SADI code for lifecourse sequence analysis in #Stata (categorical time-series stuff, in effect).
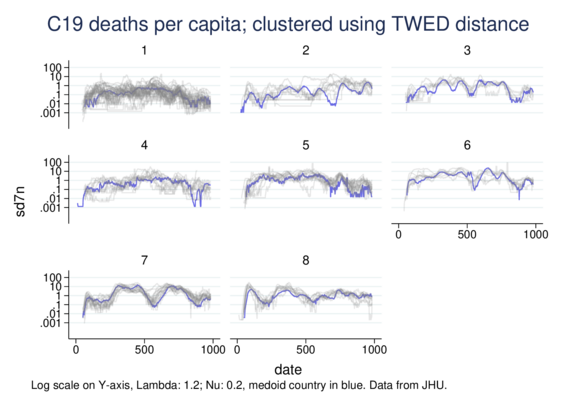
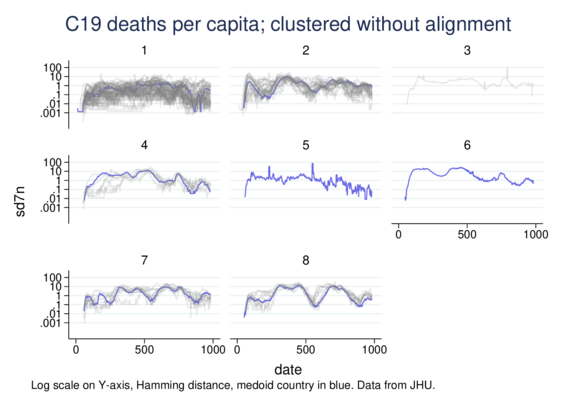
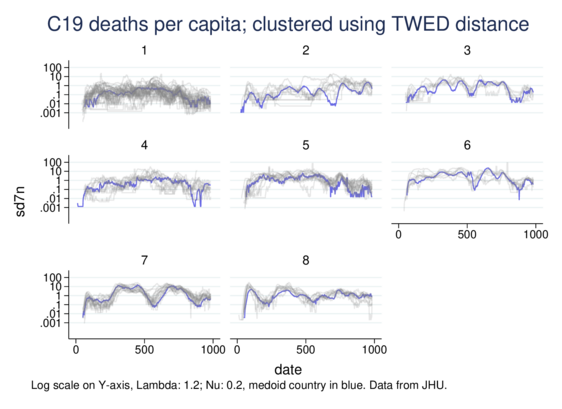
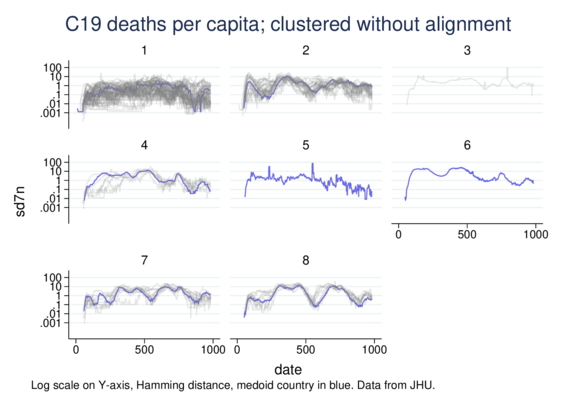
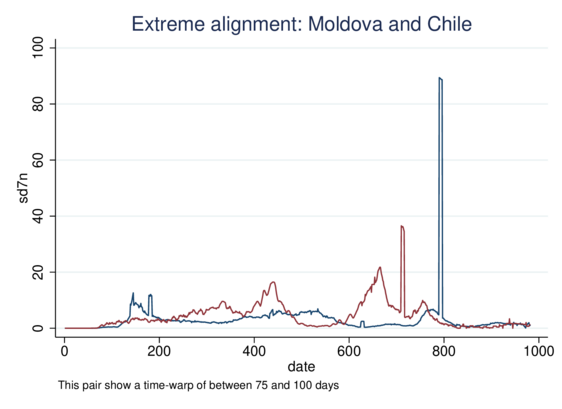
As a side exercise I adapted the TWED distance measure for continuous variables, not just categorical. Time Warp Edit Distance stretches and compresses the time axis to calculate similarity in time-series, allowing recognition of similarity displaced in time (with penalisation).
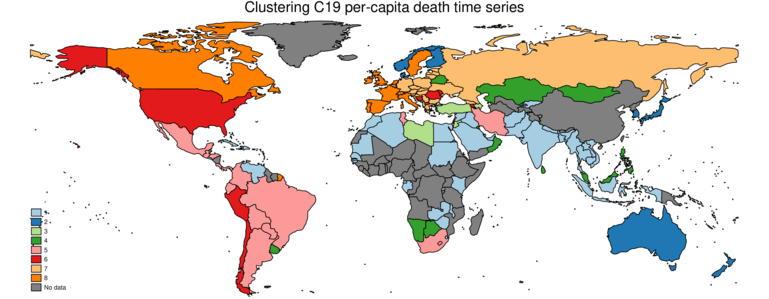
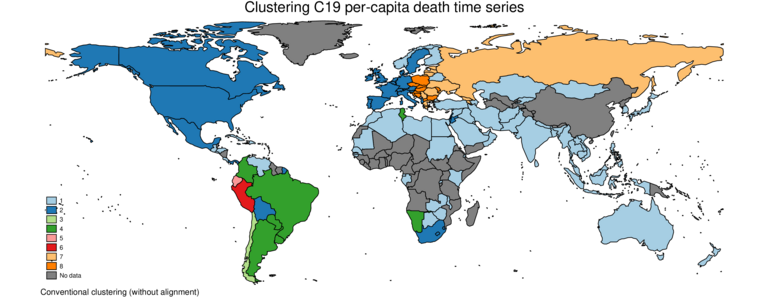
Here I cluster country-level COVID19 data, specifically per-million daily death rates.