Holy _shit_ this paper, and the insight behind it.
You know how every receiver is also a transmitter, _well_: every text predictor is also text compressor, and vice-versa.
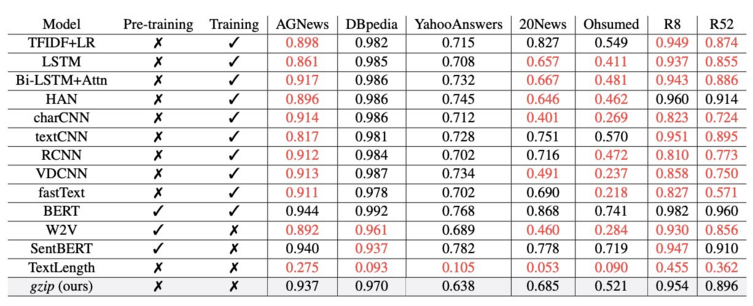
You can outperform massive neural networks running millions of parameters, with a few lines of python and a novel application of _gzip_.