New paper on the implicit bias (or lack thereof) of stochastic gradient descent in the online learning setting https://arxiv.org/abs/2306.08590
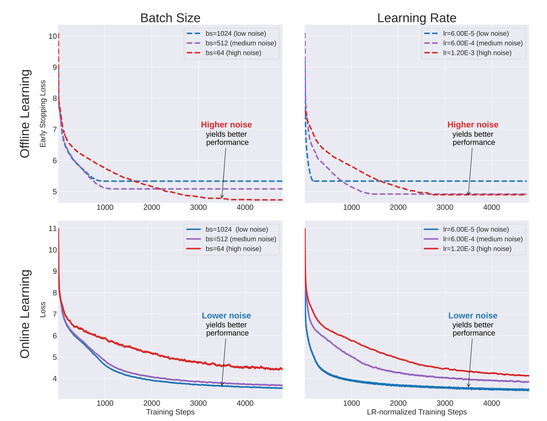
We show that aside from the computational benefits, SGD noise (larger learning rate or smaller batches) do not offer implicit bias advantages.
With Nikhil Vyas, Depen Morwani, Rosie Zhao, Gal Kaplun, and Sham Kakade.

Beyond Implicit Bias: The Insignificance of SGD Noise in Online Learning
The success of SGD in deep learning has been ascribed by prior works to the implicit bias induced by finite batch sizes ("SGD noise"). While prior works focused on offline learning (i.e., multiple-epoch training), we study the impact of SGD noise on online (i.e., single epoch) learning. Through an extensive empirical analysis of image and language data, we demonstrate that small batch sizes do not confer any implicit bias advantages in online learning. In contrast to offline learning, the benefits of SGD noise in online learning are strictly computational, facilitating more cost-effective gradient steps. This suggests that SGD in the online regime can be construed as taking noisy steps along the "golden path" of the noiseless gradient descent algorithm. We study this hypothesis and provide supporting evidence in loss and function space. Our findings challenge the prevailing understanding of SGD and offer novel insights into its role in online learning.