This visual deep dive into one of the largest AI language datasets is nonstop fascinating, jaw-dropping, and troubling, and anyone who is remotely interested in how LLMs really work, their biases, or intellectual property should read it. https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/

"Content without consent" is a concern that I could see catching on as more people gradually realize the content they've published and posted over the years is being secretly used to train for-profit AI models. https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/

If your AI chatbot is spouting some disturbing views, it could be because the websites that contributed the most language tokens to its training dataset include the likes of RT, Breitbart and VDare.

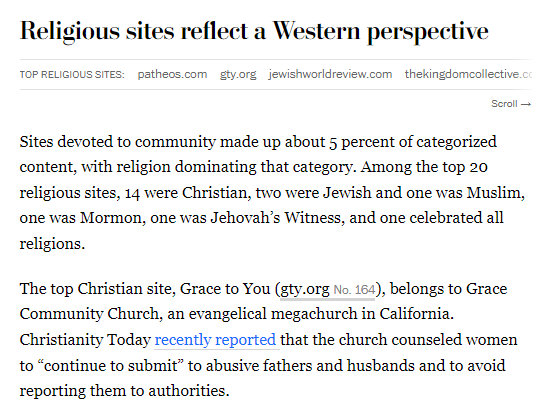
If you're asking an AI chatbot questions about religion, you probably shouldn't expect the perspectives of non-Christian faiths to be well-represented, based on this analysis of what sites make up Google's massive C4 dataset. https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/
Is your website / your favorite website / your least favorite website being scraped to train tech giants' AI models? You might be surprised. This story has a handy search tool you can use to see if a given domain is included in one of the largest datasets. https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/
Why aren't the big social networks up in arms about rival tech giants scraping their content to train AI models? Maybe because they don't allow it--and they may be keeping it partly to train their own models. https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/

If you're concerned by what's in Google's colossal C4 dataset, keep in mind it's only a small fraction of the training data for today's AI chatbots--and OpenAI won't even tell us what it's using for ChatGPT and GPT-4.

So why aren't the big AI companies more transparent about what's in the data that they use to train their models?
One reason, experts say, is because they're afraid they'd get in trouble if people found out. https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/

Sorry for barraging your feed with this... tootstorm? I don't do it often. But I found this story by @kevinschaul, @nitashatiku, and Szu Yu Chen really eye-opening and valuable and realized it might be a large ask for people to read the whole thing, so I wanted to highlight some of what I found the most interesting takeaways. Thanks for your patience.
@willoremus @kevinschaul @nitashatiku It’s really very good; subject of repeated discussion in the ML track at the open source lawyer conference I’m at today.
The challenge I keep coming back to: this media scrutiny is critical to a functioning societal oversight of this new tech, but such scrutiny incentivizes other cos to stop disclosing their data sets. That’s a bad spiral to be in.