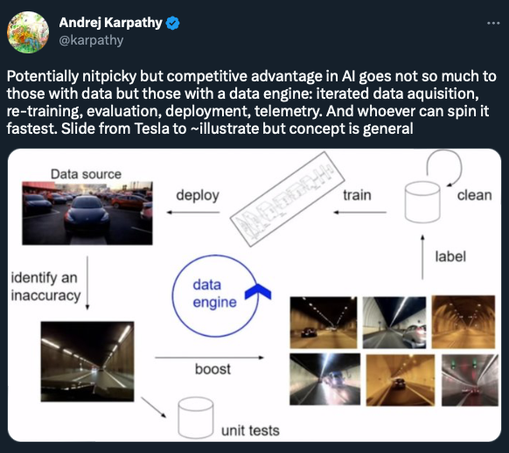
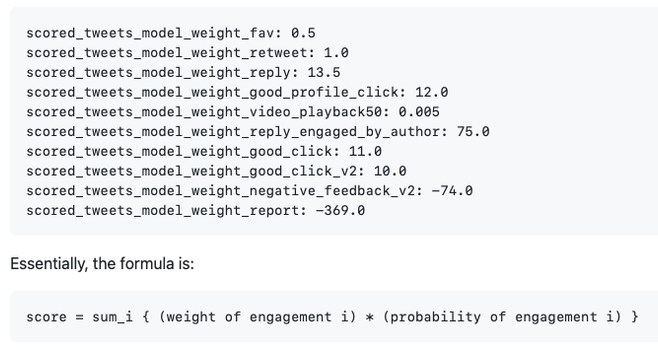
What are some design patterns in machine learning systems?
Here are a few I've seen:
1. Cascade: Break a complex problem into simpler problems. Each subsequent model focuses on more difficult or specific problems.
Stack Exchange has a cascade of defenses against spam: https://stackoverflow.blog/2020/06/25/how-does-spam-protection-work-on-stack-exchange/
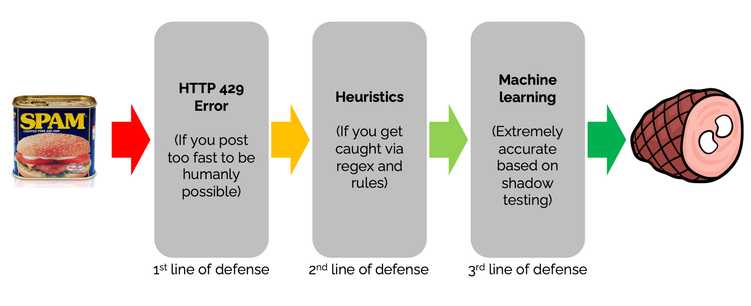

How does spam protection work on Stack Exchange?
If you put a textbox on the Internet, someone will put spam in it. If you put a textbox on a site that gets millions of hits a day, lots of someones will put lots of spam in it. So Stack Exchange uses multiple layers to block all the spam coming in.