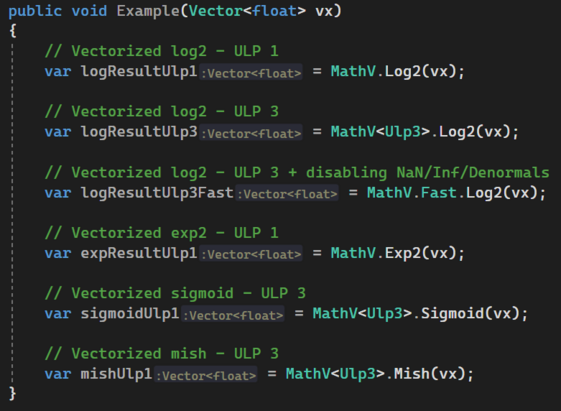
I have spent my last evenings optimizing my C# .NET 7 vectorized exp2 and log2, by improving their precision to 1 ULP (in addition to 3) and by allowing to parameterize over it, so that codegen gets nicely monomorphized
I compared it with SLEEF, that I used partly to optimize further. It's crazy how many code out there with exp2 and log2 are sometimes wrong or not as optimized!
I can now continue building higher level blocks for my tensor lib with activation functions for neural networks! 🏎️