Tabular data can benefit from merging external sources of information.
The FeatureAugmenter is a sklearn transformer to augment a given dataframe by joins on reference tables.
https://dirty-cat.github.io/stable/generated/dirty_cat.FeatureAugmenter.html
fuzzy_join makes it robust to mismatch in vocabulary. Hyperparameter optimization can tune matches for prediction
For such external information,
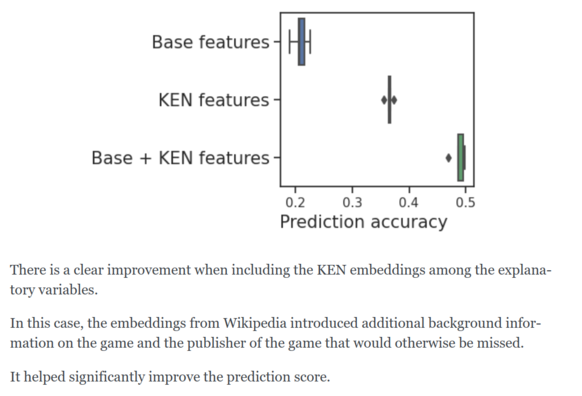
diry-cat can download embeddings of wikipedia data on millions of entities: companies, cities, geographic locations...
https://dirty-cat.github.io/stable/auto_examples/07_ken_embeddings_example.html