I just learned that in JavaScript `fetch` requests you can use the HEAD method to figure out if a file can be downloaded before actually downloading the actual file.
It’s just like using GET, but you only get header information: https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods/HEAD
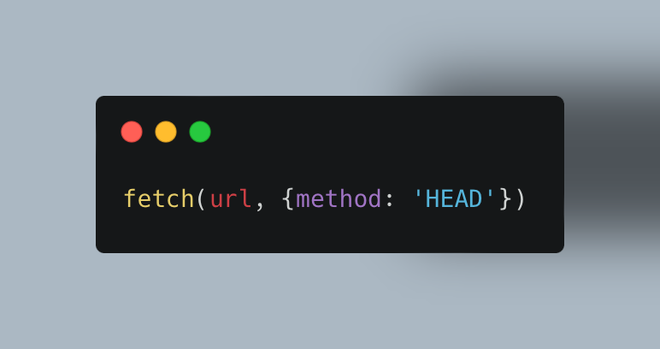

HEAD - HTTP | MDN
The HTTP HEAD method requests the headers that would be returned if the HEAD request's URL was instead requested with the HTTP GET method. For example, if a URL might produce a large download, a HEAD request could read its Content-Length header to check the filesize without actually downloading the file.