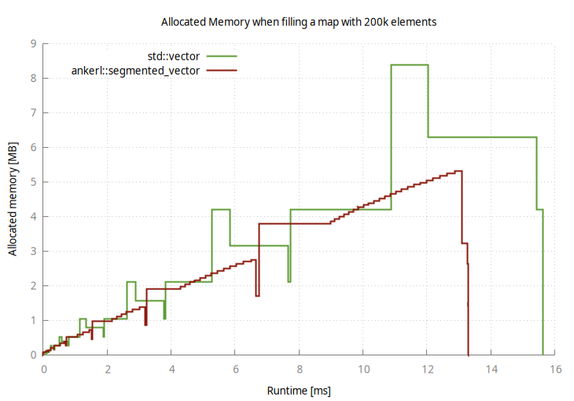
Working on an alternative std::vector implementation that's not contiguous and can be the base for my ankerl::unordered_dense::map. https://github.com/martinus/unordered_dense
The big advantage is it doesn't have allocation spikes. Surprisingly, insertion is faster because no elements have to be moved around #cpp