Here's something to kick things off over here: in a new paper, we found that GPT-3 matches or exceeds human performance on zero-shot analogical reasoning, including on a text-based version of Raven's Progressive Matrices.
https://arxiv.org/abs/2212.09196v1

Emergent Analogical Reasoning in Large Language Models
The recent advent of large language models has reinvigorated debate over
whether human cognitive capacities might emerge in such generic models given
sufficient training data. Of particular interest is the ability of these models
to reason about novel problems zero-shot, without any direct training. In human
cognition, this capacity is closely tied to an ability to reason by analogy.
Here, we performed a direct comparison between human reasoners and a large
language model (the text-davinci-003 variant of GPT-3) on a range of analogical
tasks, including a novel text-based matrix reasoning task closely modeled on
Raven's Progressive Matrices. We found that GPT-3 displayed a surprisingly
strong capacity for abstract pattern induction, matching or even surpassing
human capabilities in most settings. Our results indicate that large language
models such as GPT-3 have acquired an emergent ability to find zero-shot
solutions to a broad range of analogy problems.
Analogical reasoning is often viewed as the quintessential example of the human capacity for abstraction and generalization, allowing us to approach novel problems *zero-shot*, by comparing them to more familiar situations.
Given the recent debates surrounding the reasoning abilities of LLMs, we wondered whether they might be capable of this kind of zero-shot analogical reasoning, and how their performance would stack up against human participants.
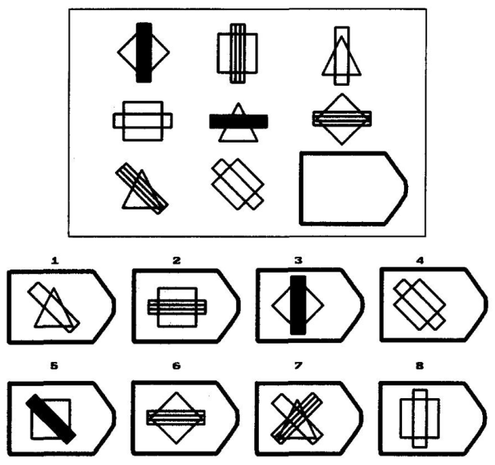
We focused primarily on Raven's Progressive Matrices (RPM), a popular visual analogy problem set often viewed as one of the best measures of zero-shot reasoning ability (i.e., fluid intelligence).
We created a text-based benchmark -- Digit Matrices -- closely modeled on RPM, and evaluated both GPT-3 and human participants.
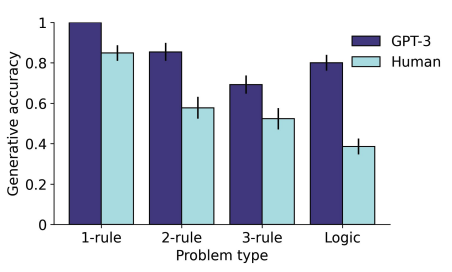
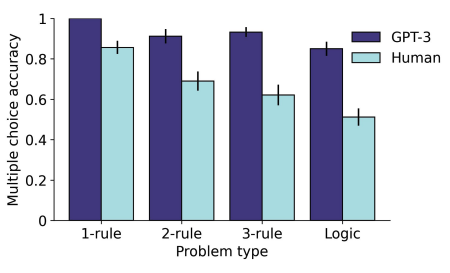
GPT-3 outperformed human participants both when generating answers from scratch, and when selecting from a set of answer choices. Note that this is without *any* training on this task.
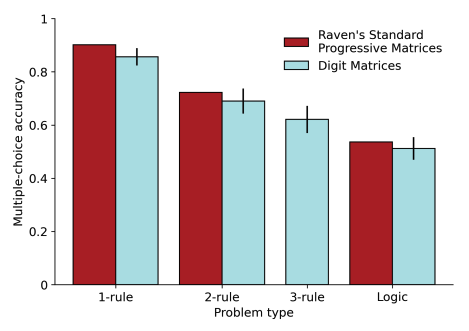
We also found that the pattern of human performance on this new task was very close to the pattern seen for standard (visual) RPM problems, suggesting that this task is tapping into similar processes.
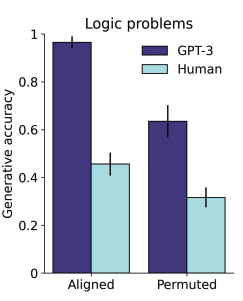
GPT-3 also displayed several qualitative effects that were consistent with known features of human analogical reasoning. For instance, it had an easier time solving logic problems when the corresponding elements were spatially aligned.
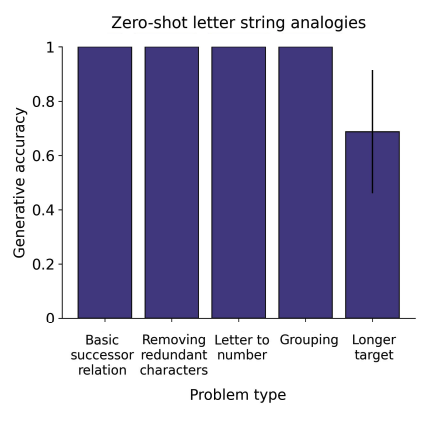
Finally, we also tested GPT-3 on letter string analogies. @melaniemitchell previously found that GPT-3 performed very poorly on these problems:
https://medium.com/@melaniemitchell.me/can-gpt-3-make-analogies-16436605c446
but it seems that the newest iteration of GPT-3 performs much better.

Can GPT-3 Make Analogies? - Melanie Mitchell - Medium
By Melanie Mitchell. “Can GPT-3 Make Analogies?” is published by Melanie Mitchell.
Overall, we were shocked that GPT-3 performs so well on these tasks. The question now of course is whether it's solving them in anything like the way that humans do. Does GPT-3 implement, in an emergent way, any of the features posited by cognitive theories, e.g. relational representations, variable-binding, analogical mapping, etc., or has it discovered a completely novel way of performing analogical reasoning? (or are these cognitive theories wrong?) Lots to investigate.